Agent Memory: Permission vs Purpose Failure Modes
Permission to access memory isn't purpose. Why AI agents fail silently when memory systems grant access but lack task context.
GLM-5.2: The New Leading Open-Weights LLM in 2026
GLM-5.2 tops the open-weights leaderboard with a 51 Intelligence Index, 1M context, and MIT license. Benchmarks vs DeepSeek V4 Pro and Kimi K2.6.

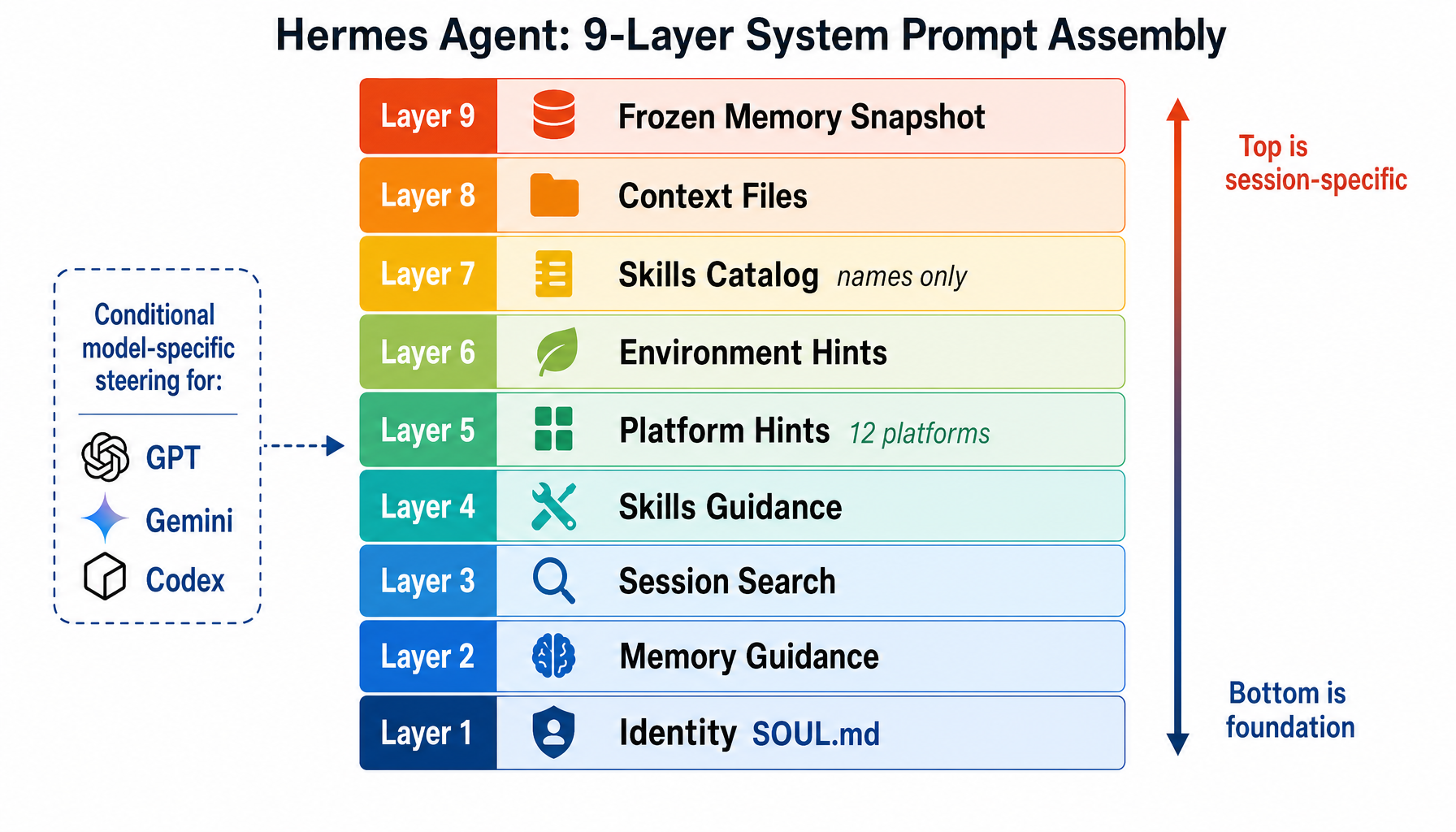
Inside Hermes Agent: How Self-Improving Skills Work
How Hermes Agent turns finished sessions into reusable skills, using a background review agent, on-demand skill memory, and a four-layer memory system.
LangSmith vs Langfuse vs Phoenix: LLM Observability
Your agent failed in prod and you can't reproduce it. Compare LangSmith, Langfuse, and Phoenix on tracing, evals, self-hosting, and cost.

SmallCode: 87% Benchmark AI Agent with 4B Parameters
Deep dive into SmallCode's architecture: how a 4B-parameter coding agent achieves frontier-model benchmarks through specialized training and inference optimization.

langchain-mcp-adapters: Fix ToolException Errors
Debug langchain-mcp-adapters ToolException errors fast. Causes, code fixes, and a checklist for connecting LangChain agents to MCP servers.
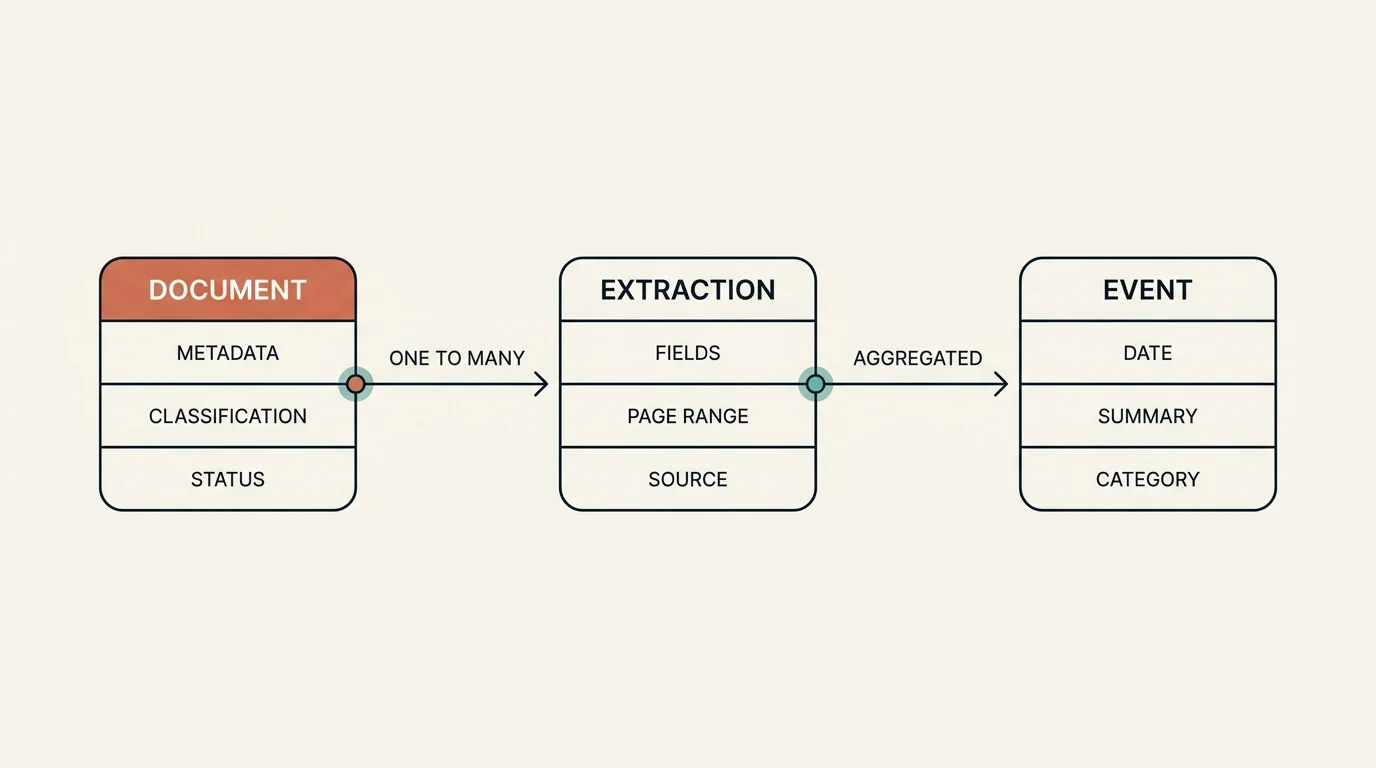
IDP Part 2: Routing, Extraction & Timeline Generation
The action half of a production IDP pipeline: skip-routing, structured extraction, day-by-day timeline assembly, plus the queues and retries that scale it.
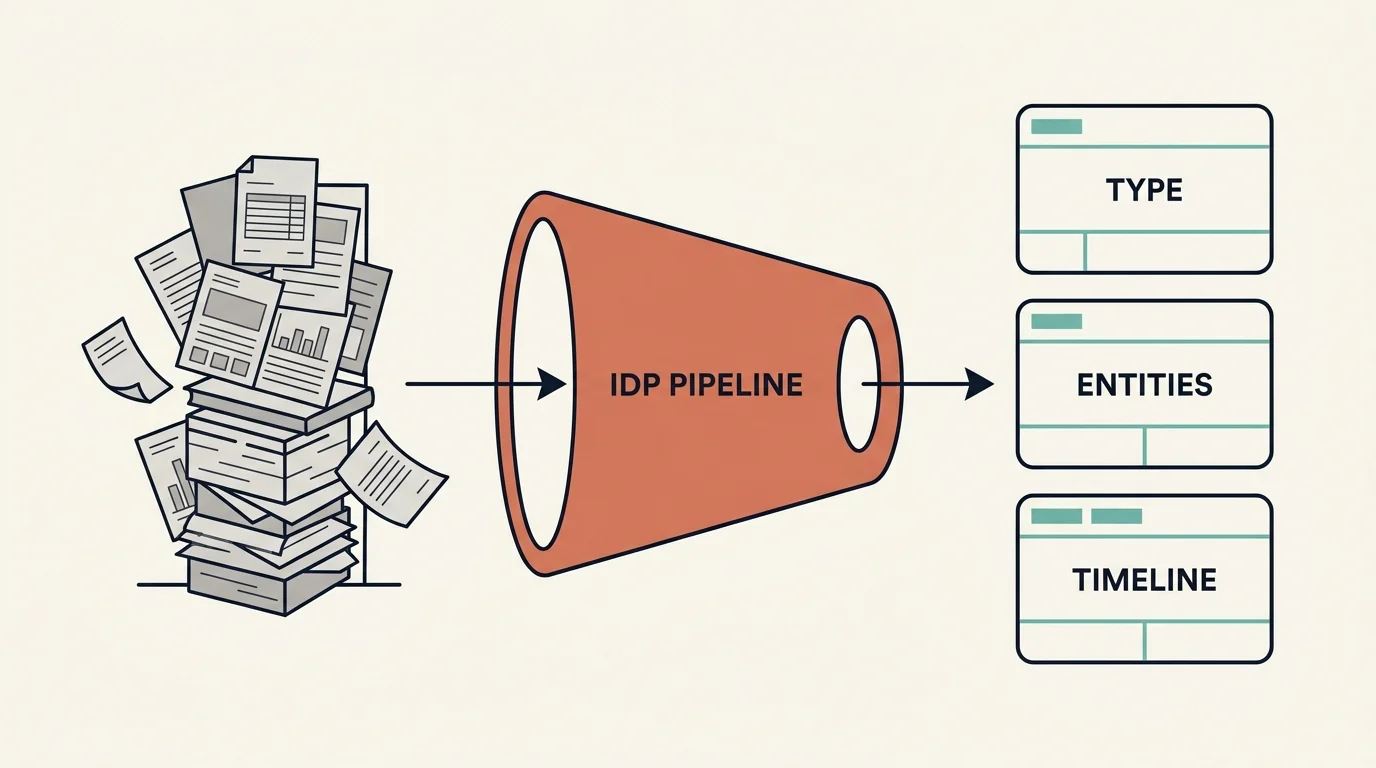
Intelligent Document Processing: OCR & AI Classification
How a production IDP pipeline turns 500-page medical-legal bundles into structured data with OCR and a 3-level LLM classification hierarchy.
Local AI Coding Agents vs Cloud: Small Model Guide 2026
Compare local AI coding agents using 4B-14B models against cloud agents like Claude Code and Copilot. Benchmarks, architecture, and cost analysis.

Gemini 3.5 Flash vs Claude Sonnet vs GPT-4.1 Mini 2026
Compare Gemini 3.5 Flash, Claude Sonnet 4.6, and GPT-4.1 Mini on speed, cost, quality, and tool calling. Benchmarks and code examples.

Small Tool Calling Models: Edge AI Guide 2026
Compare Needle 26M, FunctionGemma 270M, Qwen 0.6B, and Granite 350M for on-device tool calling. Architecture and benchmarks.

JS/TS GenAI Frameworks: 2026 Comparison
Compare top JS/TS GenAI frameworks for 2026. Vercel AI SDK, LangChain.js, Mastra, GenKit, and LlamaIndex.TS benchmarked.
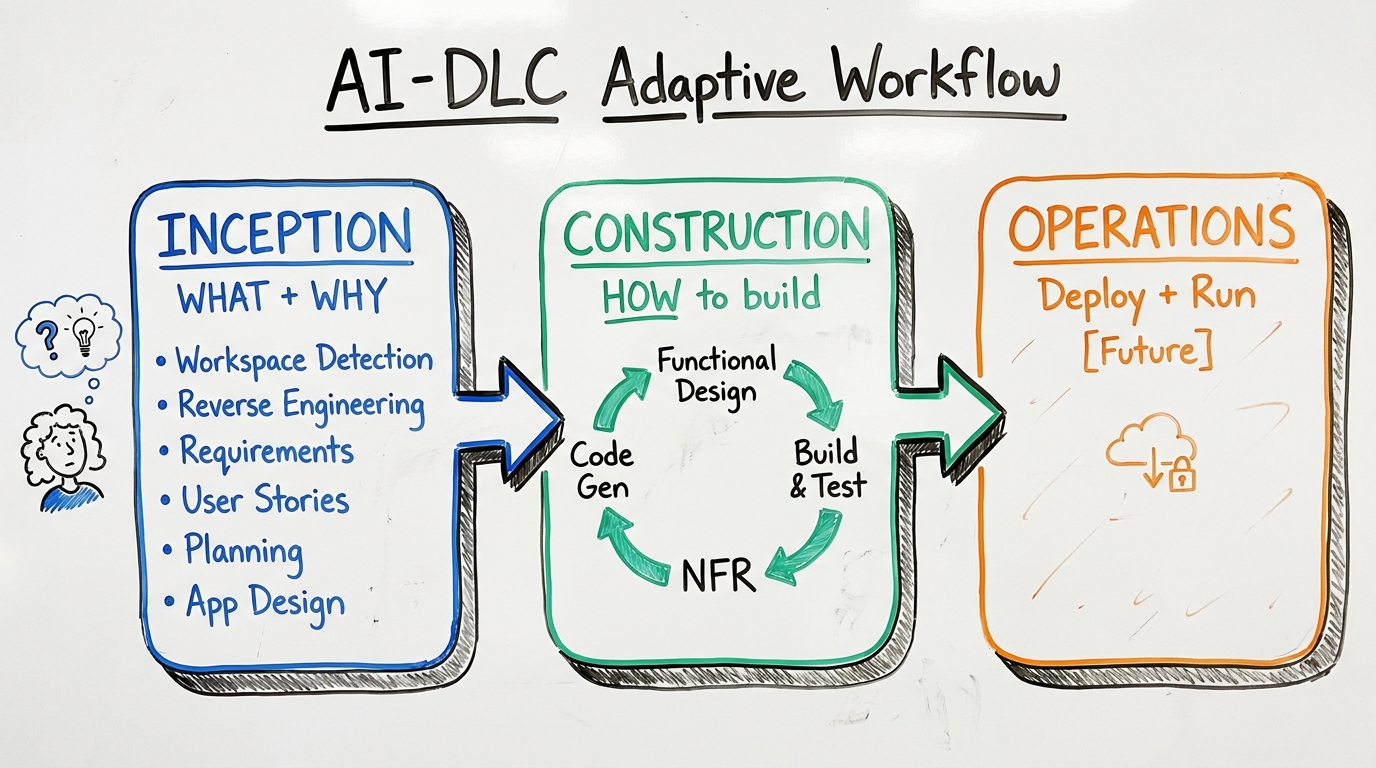
AWS AI-DLC: The Agentic Dev Lifecycle That Works Everywhere
Master AWS AI-DLC for disciplined AI pair-programming. Works across Kiro, Cursor, Claude Code, and Copilot with zero lock-in.
Browser Use vs Stagehand vs Playwright MCP Tested 2026
Which AI browser automation tool should you use in 2026? We compare Browser Use, Stagehand, and Playwright MCP with code, token costs, and trade-offs.
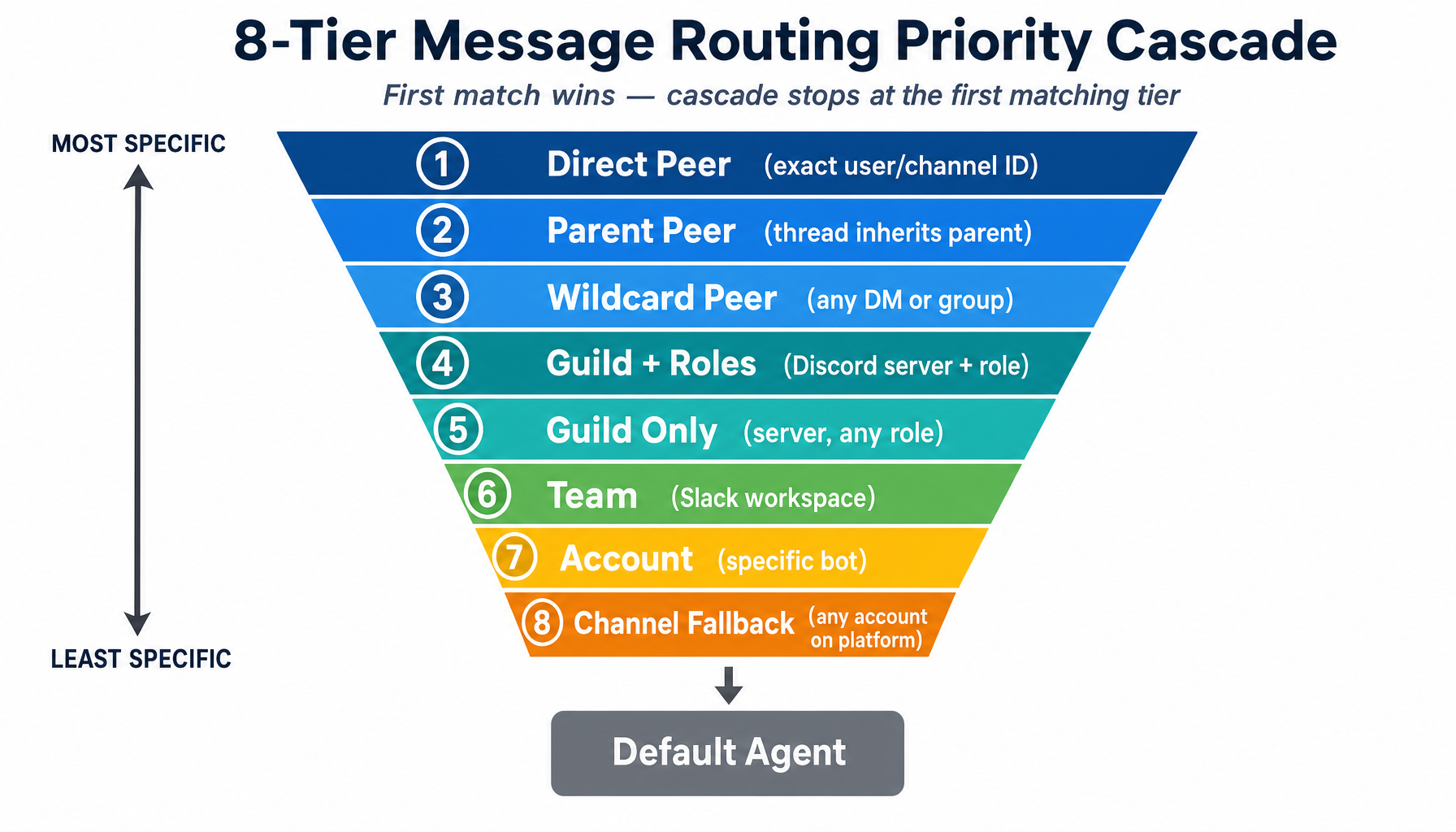
OpenClaw Architecture: 8-Tier Routing & Sandbox Deep Dive
Explore OpenClaw's 8-tier message routing across Discord, Telegram, and Slack with pluggable Docker/SSH sandbox isolation.
OpenClaw vs Hermes: Context Compression Cuts Cost 75%
See how two top AI agents cut token costs ~75% using prompt caching, frozen memory, and 5-phase context compression — with real source code.
AI Coding Agent Architecture: Agent Loop Deep Dive
Explore how Claude Code, Cursor, Aider, and Cline work under the hood. Agent loops, tool dispatch, and edit strategies explained.

GPT Image 2 vs Gemini 3 Pro Benchmark 2026
Compare GPT Image 2 vs Gemini 3 Pro across 8 categories. Gemini is 4x faster, GPT has better detail. Full results with outputs.

AI Agent Memory: Why Binding Matters More Than Recall
Discover why AI agent memory fails at binding, not recall. 500+ experiments reveal architecture patterns that fix context-action gaps.

AgentCore vs LangGraph: Agent Orchestration Compared (2026)
Compare AgentCore and LangGraph for AI agent orchestration. State management, deployment, and pricing explained with code.

AgentCore vs LangChain: 2026 Framework Guide
Compare AgentCore and LangChain for AI agents. Architecture, pricing, and deployment trade-offs explained with code.
Context Engineering for AI Agents: 6 Techniques That Cut Our Costs 10x
One misplaced timestamp invalidated our entire KV cache and 10x'd our bill. Here are 6 context engineering patterns from Manus and production agent teams that prevent exactly this -- with code examples.