OpenClaw vs Hermes: How AI Agents Cut Tokens 75%
OpenClaw vs Hermes Agent: how two top open-source agents cut token costs ~75% with prompt caching, frozen memory, and 5-phase context compression.
OpenClaw vs Hermes Agent: Prompt Composition and Context Compression Compared
TL;DR: OpenClaw (365K stars) and Hermes Agent by Nous Research (121K stars) are the two most popular open-source AI agent platforms in 2026. Both face the same core challenges — building system prompts that guide agent behavior without burning tokens, and compressing conversations when they outgrow the context window. But they solve these problems differently. OpenClaw builds ~25-section prompts with an explicit cache boundary marker, while Hermes uses a 9-layer assembly with frozen memory snapshots for prompt cache stability. For compression, OpenClaw chunks-splits-and-merges, while Hermes runs a 5-phase pipeline that prunes tool results cheaply before calling the LLM. This article walks through both architectures with source code analysis from OpenClaw and Hermes Agent.
Key Takeaways
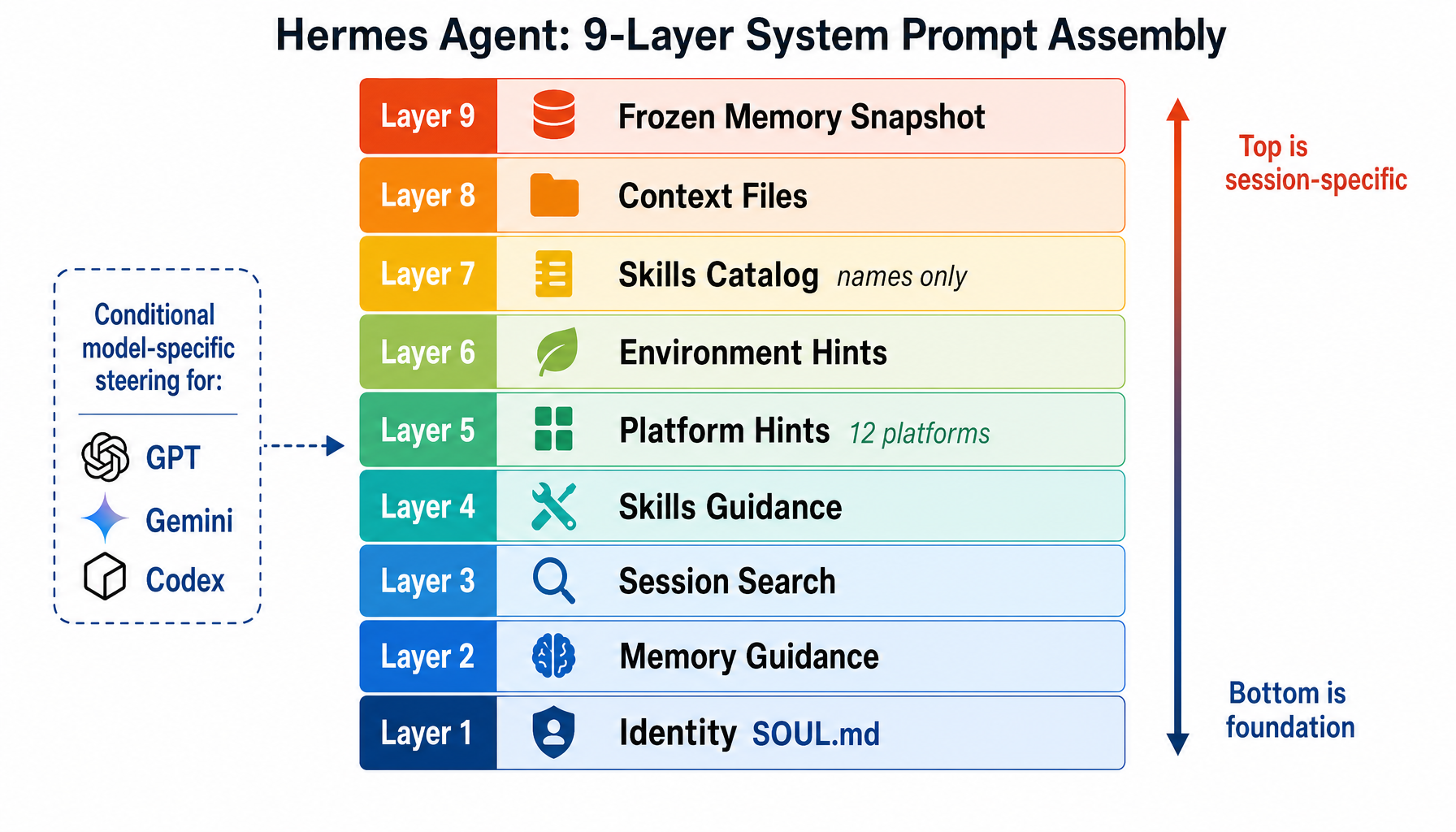
- Hermes assembles its system prompt from 9 discrete layers (identity → memory guidance → skills → platform hints → context files → frozen memory), with each layer adding specific context in a deliberate order.
- OpenClaw composes ~25 sections split by an explicit cache boundary marker — stable content above the line gets cached across turns, volatile content below is rebuilt each turn.
- Hermes uses progressive 3-tier skill disclosure: skill names in the system prompt (~300 tokens), full instructions loaded on demand (~2K tokens), and specific reference files when needed (~500 tokens) — saving ~99% of token cost vs loading all skills upfront.
- Hermes freezes memory at session start — mid-session writes don't change the system prompt, preserving the prompt cache and reducing input token costs by ~75% over multi-turn conversations.
- For context compression, Hermes runs a 5-phase pipeline starting with cheap tool-result pruning (no LLM call) before using LLM summarization on only the remaining middle zone, with anti-thrashing protection that stops compressing if two consecutive passes save less than 10%.
- OpenClaw uses a chunk-split-summarize-merge approach with adaptive chunk ratios, explicit identifier preservation instructions, and a 3-tier fallback strategy (full → partial → static summary).
The Shared Problem: Tokens Are Finite
Every AI agent faces two token budget challenges. First, the system prompt must guide behavior without consuming a disproportionate share of the context window. A 50-skill agent that loads all skill instructions upfront wastes thousands of tokens on irrelevant content. Second, conversations inevitably grow until they hit the model's context limit. At that point, the system must compress — keeping critical information while discarding noise.
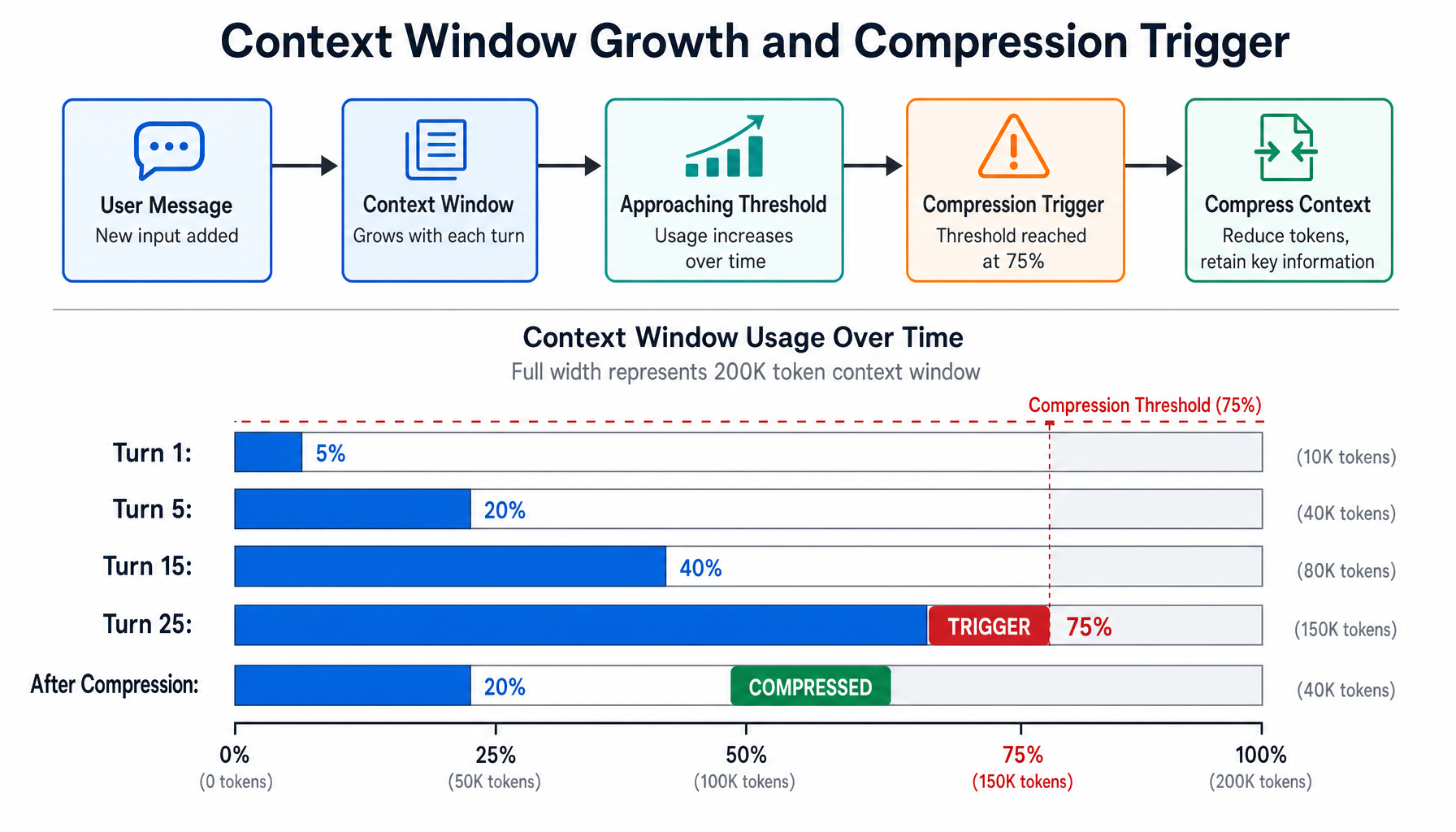
OpenClaw and Hermes both solve these problems, but their architectural choices reflect different priorities: OpenClaw optimizes for cache observability and explicit control, while Hermes optimizes for progressive disclosure and cost efficiency.
Hermes: 9-Layer Prompt Assembly
Hermes builds its system prompt from 9 layers, each adding specific context. Think of it as building a layered briefing document — each layer contributes something essential:

Layer 1 — Identity (SOUL.md): The agent's personality and role definition. Custom SOUL.md from ~/.hermes/SOUL.md overrides the default.
Layer 2 — Memory Guidance: Instructions for how the agent should use its memory system: "Save preferences, not progress. Declarative facts, not imperatives."
Layer 3 — Session Search Guidance: Instructions for using session_search to find context from past conversations.
Layer 4 — Skills Guidance: Rules for auto-saving skills after 5+ tool calls and patching stale skills when they fail.
Layer 5 — Platform Hints: Per-platform formatting rules for 12 platforms. Telegram gets markdown support and MEDIA:/path for files. WhatsApp gets plain text only. Discord gets full markdown with syntax-highlighted code blocks.
Layer 6 — Environment Hints: Runtime detection like WSL, where paths need translation between /mnt/c/ and C:\.
Layer 7 — Skills Catalog: Names and one-line descriptions only. The full content is loaded on demand (see progressive disclosure below).
Layer 8 — Context Files: Project-specific instructions from repo config files. Priority: .hermes.md > AGENTS.md > CLAUDE.md. Max 20,000 chars. Scanned for prompt injection before inclusion — 12 threat patterns plus invisible Unicode detection.
Layer 9 — Frozen Memory Snapshot: MEMORY.md and USER.md content captured at session start. This is the most architecturally significant choice — more on this below.
Hermes also injects conditional model-specific steering: GPT/Codex models get "developer" role instead of "system".
Progressive 3-Tier Skill Disclosure
If Hermes has 50+ skills and each has detailed instructions, stuffing them all into the system prompt would waste thousands of tokens. The solution is a three-tier progressive disclosure system:

Tier 1 — Always in system prompt (~300 tokens): Skill names and one-line descriptions. The agent reads these to decide which skill might be relevant.
Tier 2 — Loaded on demand (500-2,000 tokens): When the agent decides a skill matches, it calls skill_view("github-pr") to load the full instructions, steps, and linked file references.
Tier 3 — Specific file (100-500 tokens): For templates or reference data, the agent loads individual files via skill_view("github-pr", "templates/pr-body.md").
The payoff: instead of ~50,000 tokens for all skills, the system prompt uses ~300. Skills are loaded only when relevant, saving ~99% of token cost.
The skills cache uses two layers: an in-process LRU (OrderedDict, max 8 entries) for instant lookups, and a disk snapshot (~/.hermes/.skills_prompt_snapshot.json) with mtime/size validation that survives process restarts.
The Frozen Memory Pattern
Hermes freezes memory at session start. Mid-session writes update the underlying files, but the system prompt snapshot doesn't change until the next session. This is the key to prompt cache efficiency:
This yields ~75% reduction in input token costs over multi-turn conversations. The trade-off is that new memory entries aren't visible to the system prompt until the next session — but they're still available via the memory tool.
OpenClaw: 25-Section Prompt with Cache Boundary
OpenClaw takes a different approach — it composes ~25 discrete sections and inserts an explicit cache boundary marker:
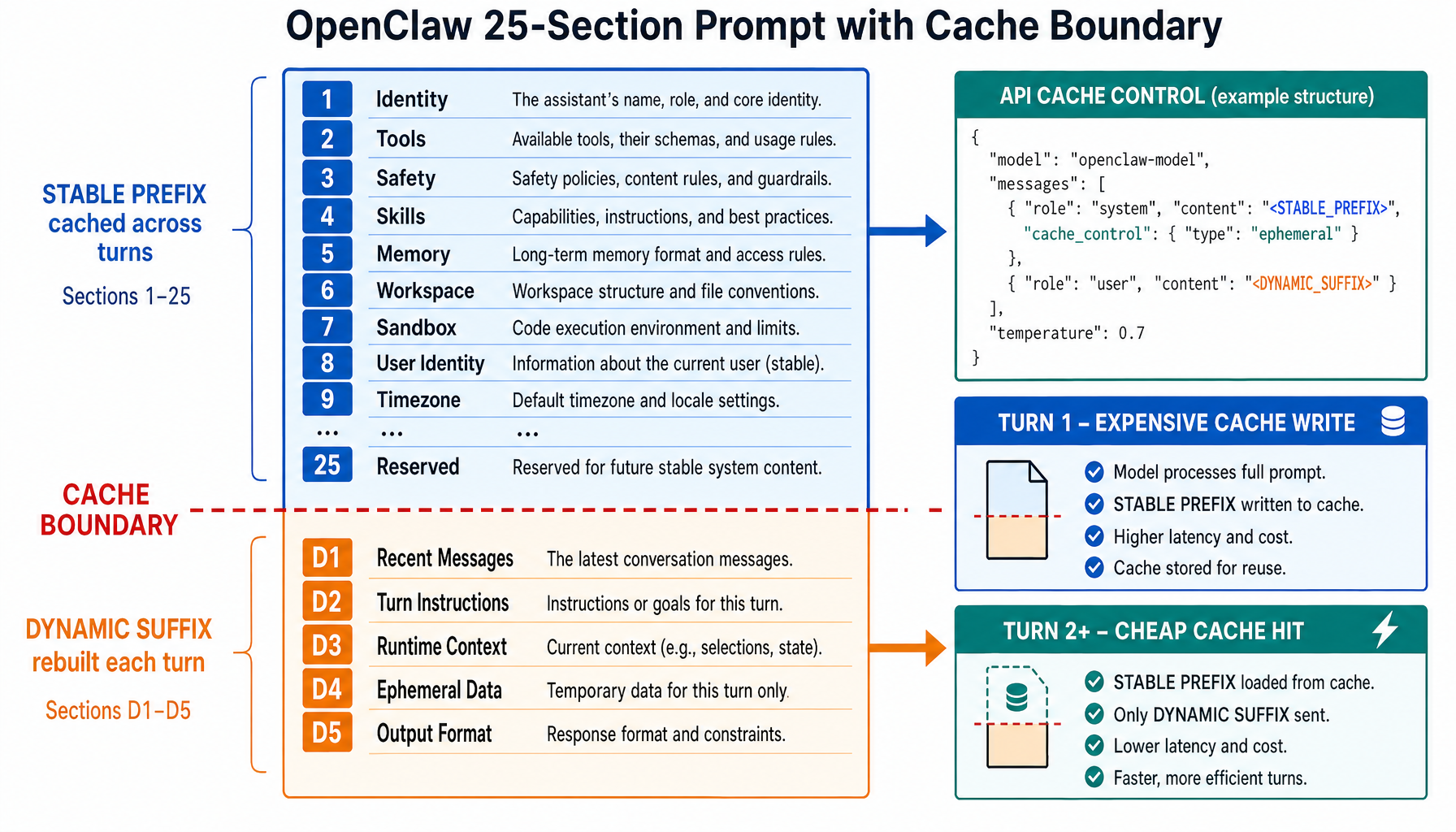
Everything above the marker is stable across turns: identity, tool listings, execution bias rules, safety rules, skills, memory, workspace config, sandbox constraints, user identity (SHA-256 hashed sender IDs), timezone, and more. Everything below is dynamic: heartbeat data, group chat context, provider-specific suffixes, and the runtime line (agent ID, host, OS, model).
At the API level, the stable prefix gets cache_control: { type: "ephemeral" }, enabling KV cache reuse across turns. OpenClaw even has a prompt cache observability system that takes SHA-256 digests of the system prompt and tracks hits vs. misses, detecting "cache breaks" when cacheRead drops more than 5%.
Context file ordering uses a priority map:
Files in DYNAMIC_CONTEXT_FILE_BASENAMES (currently only heartbeat.md) are separated and placed below the cache boundary because they change frequently.
Prompt Composition Compared
The analogy: OpenClaw is a well-organized filing cabinet — 25 labeled drawers with a divider separating rarely-changed from daily-changed content. Hermes is a layered briefing document — 9 sections in deliberate order, with a table of contents for skills (read full chapters on demand) and a morning photocopy of memory (won't change today).
Hermes: 5-Phase Context Compression
When a conversation grows too long, Hermes compresses it through a 5-phase pipeline:
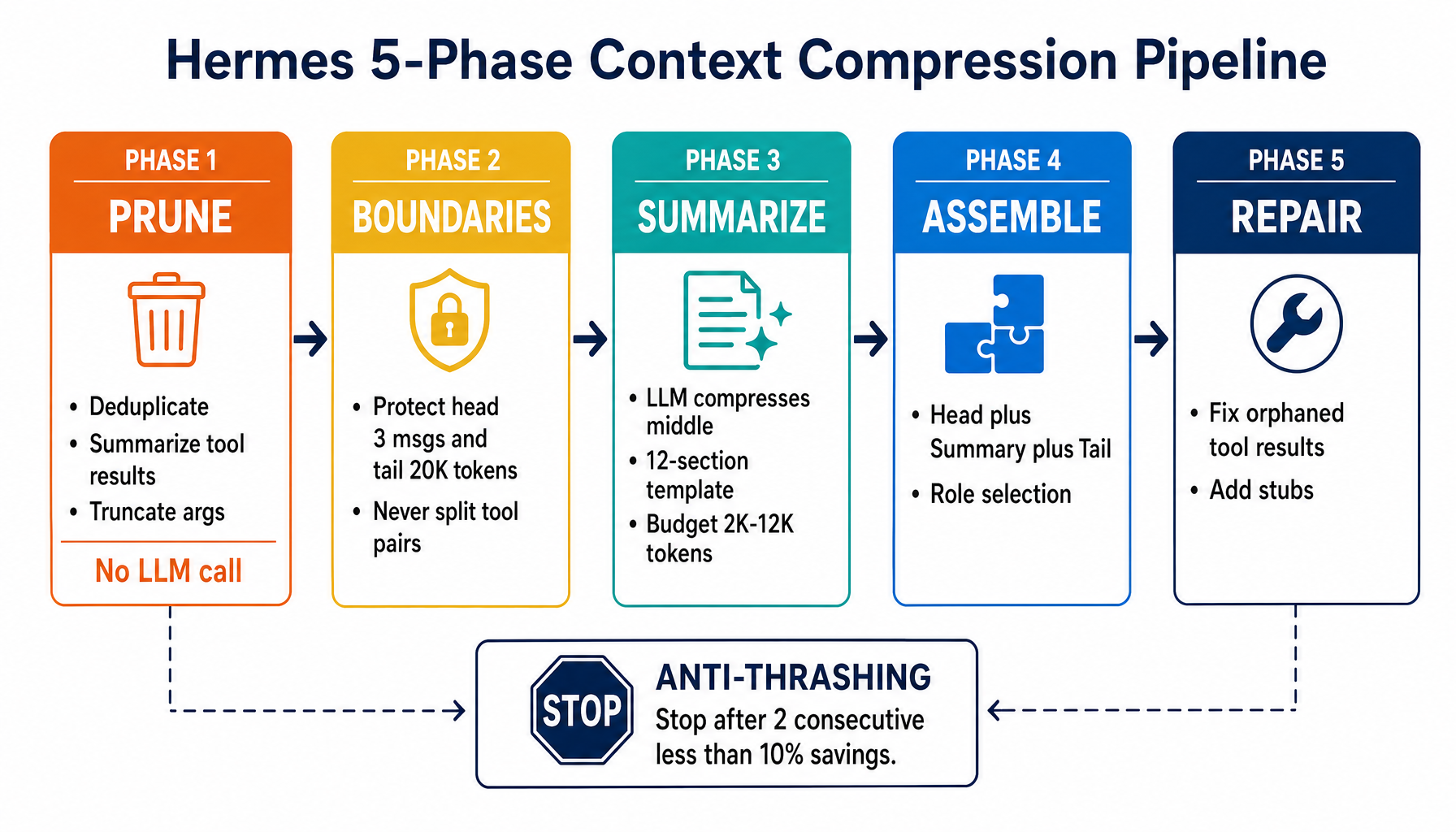
Phase 1: Tool Result Pruning (No LLM Call)
Old tool outputs are replaced with informative one-liners. Three sub-passes:
- Deduplication: MD5 hashes of tool results. Duplicate content (>200 chars) becomes `"[Duplicate tool output]"`.
- Summarization: 20+ tool-specific handlers. `npm test` output (47 lines) becomes `"[terminal] ran npm test → exit 0, 47 lines"`. A 1,200-char file read becomes `"[read_file] read config.py (1,200 chars)"`.
- Argument truncation: Tool call args over 500 chars are parsed as JSON, string values truncated, and re-serialized. This JSON-aware approach prevents broken JSON that caused infinite retry loops (bug #11762).
Phase 2: Boundary Determination
The algorithm protects both ends of the conversation:
- Head: First 3 messages (system prompt + initial exchange), pushed forward past orphan tool results.
- Tail: ~20K token budget, walking backward from the end. Hard minimum of 3 messages. The last user message is always in the tail (fixing bug #10896 where the user's task "disappeared").
- Middle: Everything between head and tail — this gets compressed.
Phase 3: LLM Summarization
The middle zone is sent to a fast model with a structured 12-section template:
The summary is framed as being "for a DIFFERENT assistant" — preventing the summarizer from trying to respond to questions in the conversation. Sensitive data is redacted both before and after summarization.
Phase 4: Message Assembly
The compressed conversation becomes [Head] + [Summary] + [Tail]. Role selection ensures no consecutive same-role messages: if the last head message is assistant, the summary gets the user role, and vice versa.
Phase 5: Integrity Repair
Compression can break tool_call/result pairs. The sanitizer removes orphaned tool results (call was deleted) and adds stub results for calls whose results were deleted: "[Result from earlier conversation — see context summary above]".
Anti-Thrashing Protection
If compression keeps running but barely helps, it stops:
On subsequent compressions, the previous summary is included and updated incrementally — preserving existing information while adding new completed actions.
OpenClaw: Chunk-Split-Summarize-Merge
OpenClaw takes a different compression approach:
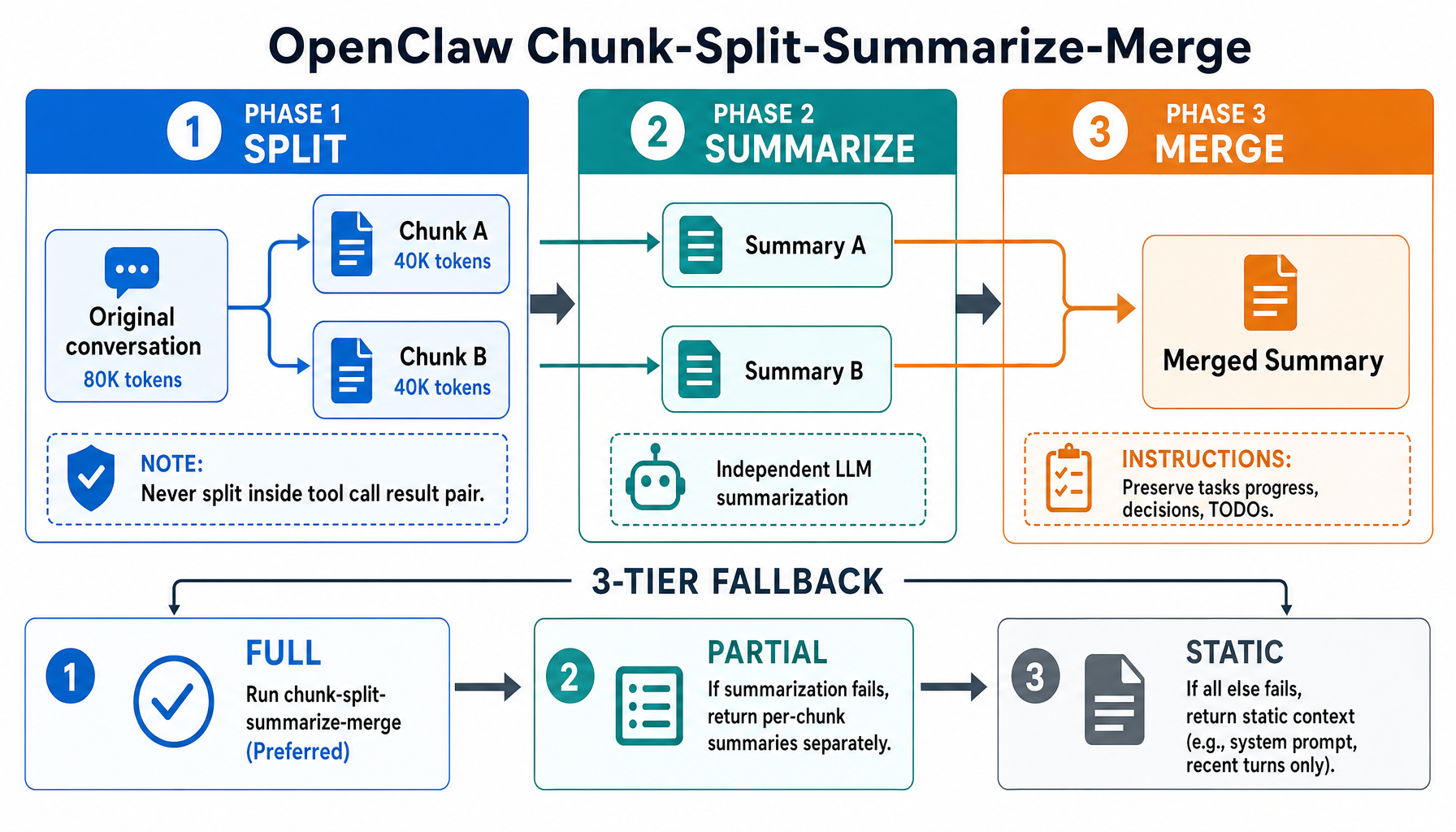
Phase 1: Split
The conversation divides into N chunks (default 2) by token count, never splitting inside a tool_call/result pair:
An adaptive chunk ratio adjusts for message sizes: normal messages (avg 3K tokens) use 40% of context per chunk; large messages (avg >10% of context each) shrink to max(0.15, 0.40 - avgRatio × 2) to avoid overflowing the summarizer. Token estimation uses chars/4 with a 20% safety margin.
Phase 2: Summarize Each Chunk
Each chunk is independently summarized with explicit identifier preservation:
"Preserve all opaque identifiers exactly as written (no shortening or reconstruction), including UUIDs, hashes, IDs, hostnames, IPs, ports, URLs, and file names."
Phase 3: Merge Summaries
Partial summaries merge into one, with instructions to preserve active tasks, batch operation progress, the last user request, decisions and rationale, and TODOs. Recent context is prioritized over older history.
Fallback Strategy
If full summarization fails, OpenClaw excludes oversized messages (>50% of context) and adds a note: "[Large assistant (~45K tokens) omitted from summary]". If that also fails, a static fallback reports the message count and size limits.
Context Compression Compared
OpenClaw's approach is like a book editor who splits a manuscript into chapters, summarizes each independently, then merges the chapter summaries into a coherent synopsis. Hermes' approach is like a court reporter who first strips verbose exhibits to one-liners (cheap), then protects opening statements and closing arguments, summarizes only the middle testimony, and repairs broken cross-references.
Which Architecture Should You Study?
If you're building a multi-platform agent where cache observability and explicit prompt control matter, study OpenClaw's 25-section prompt builder with its cache boundary marker and SHA-256 digest tracking.
If you're optimizing for cost efficiency and building a skill-heavy agent, study Hermes' progressive disclosure pattern and frozen memory snapshots — the ~99% skill token savings and ~75% prompt cache improvement are hard to ignore.
For context compression, Hermes' Phase 1 (cheap tool-result pruning before LLM calls) and anti-thrashing protection are patterns every agent builder should adopt. OpenClaw's identifier preservation instructions and adaptive chunk ratios are valuable for agents that work with code and infrastructure where UUIDs and hostnames must survive compression intact.
FAQ
Why does Hermes freeze memory at session start instead of updating it live?
Prompt cache efficiency. The system prompt is the most cacheable part of every API call — it stays identical across turns. If memory writes changed the system prompt mid-session, every turn after a write would invalidate the cache, costing ~4x more in API tokens. By freezing memory at session start, Hermes guarantees cache hits for the entire session. New memory entries are still saved to disk and available via the memory tool — they just don't appear in the system prompt until the next session.
How does OpenClaw's cache boundary actually work at the API level?
OpenClaw splits the system prompt at into two text blocks. The stable prefix (everything above) gets cache_control: { type: "ephemeral" } on the Anthropic API, telling the provider to cache this block across turns. The dynamic suffix (everything below) has no cache control and is reprocessed each turn. Turn 1 writes the cache (expensive); turns 2+ hit the cache (cheap). OpenClaw tracks cache hit rates via SHA-256 digests and alerts when hits drop more than 5%.
What happens if Hermes' context compression barely saves any tokens?
Anti-thrashing protection kicks in. If two consecutive compressions each save less than 10% of tokens, Hermes stops compressing automatically. This prevents the system from burning LLM calls on diminishing returns — a compression that saves 8% but costs 2,000 tokens to generate is net negative. Compression resumes when the user starts a new session (/new) or manually triggers /compress , which allocates 60-70% of the token budget to the specified topic.
Can OpenClaw's and Hermes' compression approaches be combined?
Yes, and it would likely outperform either alone. The ideal pipeline would start with Hermes' Phase 1 (tool-result pruning — no LLM call), then use OpenClaw's adaptive chunk splitting for the remaining content, summarize each chunk with Hermes' 12-section structured template, and finish with Hermes' Phase 5 integrity repair. Adding OpenClaw's identifier preservation instructions and Hermes' anti-thrashing guard would make it robust for both code-heavy and conversation-heavy workloads.
How do OpenClaw and Hermes compare to other AI agent frameworks like AgentCore and LangChain?
OpenClaw and Hermes are full agent platforms that include prompt composition and compression as core features. AgentCore (AWS Bedrock's managed agent runtime) and LangChain (the most popular agent framework) both face the same context compression challenges but solve them differently. LangChain provides memory modules (ConversationBufferWindowMemory, ConversationSummaryMemory) that you compose into your agent, while AgentCore offers managed memory with automatic semantic search. Neither exposes the same level of prompt cache optimization that OpenClaw and Hermes achieve through frozen snapshots and explicit cache boundaries — those patterns are more commonly found in coding agent architectures where long sessions make cache efficiency critical.
Which framework should I choose for building production AI agents?
It depends on your control requirements and deployment model. Choose AgentCore if you want a fully managed AWS service with zero infrastructure management. Choose LangChain if you need the broadest ecosystem of integrations (400+ tools) and community support. Choose OpenClaw if you're building a coding agent where explicit prompt control, cache observability, and sandbox isolation are critical. Choose Hermes if you're building a skill-heavy agent where progressive disclosure and frozen memory can cut token costs by 75%+. Many production teams use multiple frameworks — LangGraph for orchestration, AgentCore for deployment, and patterns from OpenClaw/Hermes for context optimization.
What are the actual token savings from Hermes' progressive skill disclosure?
Hermes' progressive disclosure saves approximately 99% of skill-related token costs. Without disclosure, loading 50 skills × 1,000 tokens each = 50,000 tokens in every system prompt. With Tier 1 (names only) = ~300 tokens, Tier 2 (full instructions on demand) loads 2-3 skills per session on average = ~5,000 tokens total across all turns. For a 20-turn conversation, that's 300 tokens vs 1,000,000 cumulative tokens (50K × 20) — a 99.97% reduction. The actual savings depends on skill count and usage patterns, but teams report 90-99% reductions consistently.
How does OpenClaw's cache boundary marker improve observability?
OpenClaw's marker splits the system prompt into stable (above) and dynamic (below) regions, each tracked via SHA-256 digest. This gives developers precise metrics: cache hit rate per session, which turns invalidated the cache, and cumulative savings. When a session's hit rate drops >5%, OpenClaw logs a warning with the diff that broke the boundary — critical for debugging why a "small config change" suddenly 4x'd API costs. Most agents lack this visibility; cache hits/misses are opaque AWS/Anthropic metrics.
Can I implement Hermes' frozen memory pattern in my existing agent?
Yes. The core pattern: (1) snapshot memory files at session start into a variable, (2) inject that frozen snapshot into the system prompt, (3) when the agent writes memory mid-session, update the disk files but NOT the snapshot variable, (4) on next session, reload the updated files. This requires your agent framework to separate system prompt assembly (static) from memory writes (side effects). Most agent frameworks rebuild the entire prompt each turn — you'll need to refactor to assemble-once-then-append-messages. The payoff: 70-85% prompt cache hit rate improvements in multi-turn sessions.
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
OpenClaw Architecture: 8-Tier Routing & Sandbox Deep Dive
Explore OpenClaw's 8-tier message routing across Discord, Telegram, and Slack with pluggable Docker/SSH sandbox isolation.
AI Engineering, Agent FrameworksAI Coding Agent Architecture: Agent Loop Deep Dive
Explore how Claude Code, Cursor, Aider, and Cline work under the hood. Agent loops, tool dispatch, and edit strategies explained.
AI Engineering, Agent FrameworksContext Engineering for AI Agents: Cut LLM Costs 10x in 2026
Context engineering cuts AI agent costs 10x via KV cache optimization, tool masking, and 5 more patterns. Production-tested by teams running million-token workflows.
AI Engineering, Agent Frameworks