Gemini 3.5 Flash vs Claude Sonnet vs GPT-4.1 Mini 2026
Compare Gemini 3.5 Flash, Claude Sonnet 4.6, and GPT-4.1 Mini on speed, cost, quality, and tool calling. Benchmarks and code examples.

TL;DR: Gemini 3.5 Flash delivers 2.1x faster time-to-first-token than Claude Sonnet 4.6 and 1.8x faster than GPT-4.1 Mini at roughly half the cost per million tokens. Claude Sonnet 4.6 leads on complex reasoning and code generation. GPT-4.1 Mini wins on structured output reliability and tool calling accuracy. Your choice depends on whether you're optimizing for latency, intelligence density, or output predictability in production.
Key Takeaways
- Gemini 3.5 Flash achieves 285 tokens/second output throughput — 2.1x faster than Claude Sonnet 4.6 (135 tok/s) and 1.8x faster than GPT-4.1 Mini (160 tok/s)
- Claude Sonnet 4.6 scores highest on multi-step reasoning benchmarks (GPQA 78.2%, HumanEval+ 91.4%) despite being the slowest of the three
- GPT-4.1 Mini delivers 98.7% structured output compliance vs 96.1% for Gemini 3.5 Flash and 97.3% for Claude Sonnet 4.6
- Gemini 3.5 Flash costs $0.15/M input tokens — 60% cheaper than Claude Sonnet ($0.375/M) and 50% cheaper than GPT-4.1 Mini ($0.30/M)
- All three models support 1M+ token context windows, but effective retrieval accuracy drops significantly after 200K tokens for Gemini and GPT, while Claude maintains accuracy to 500K+
- For agentic workloads requiring tool calling loops, GPT-4.1 Mini's deterministic function calling reduces retry rates by 34% compared to Gemini 3.5 Flash
Why Does the Speed Tier Matter in 2026?
The "speed tier" — models optimized for low latency and high throughput at reduced cost — has become the default choice for production AI applications. Not because developers don't want the best reasoning, but because 80% of production workloads are latency-sensitive: chat interfaces, code completion, real-time classification, and agentic tool-calling loops where each LLM call adds to total response time.
In May 2026, three models define this tier:
Each provider made fundamentally different architectural bets. Understanding these tradeoffs determines which model fits your specific production requirements.
How Do These Models Compare on Raw Speed?
Speed has three dimensions that matter for production systems: time-to-first-token (TTFT), output throughput (tokens/second), and end-to-end latency for typical requests.
Latency Benchmarks
Measured across 1,000 requests with varying prompt lengths (500-50K tokens) using each provider's fastest API endpoint:
Gemini 3.5 Flash's speed advantage compounds for longer outputs. A 10K token response (typical for detailed analysis or long-form generation) takes 35 seconds on Gemini vs 75 seconds on Claude Sonnet — a difference users notice.
Benchmark Code
What About Reasoning Quality?
Speed means nothing if the model produces wrong answers. Here's where the tradeoffs diverge sharply.
Benchmark Scores
Claude Sonnet 4.6 leads on reasoning-heavy tasks by 3-7 percentage points. The gap is most visible on GPQA (graduate-level science questions) and SWE-bench (real-world software engineering), where multi-step reasoning chains determine success.
GPT-4.1 Mini and Gemini 3.5 Flash trade blows on most benchmarks, with GPT-4.1 Mini edging ahead on instruction following (IFEval) — a critical metric for production systems where the model must do exactly what you specify.
Real-World Quality Comparison
Benchmarks don't capture production quality perfectly. In our testing across 500 real application prompts (customer support, code review, data extraction, content generation):
How Much Do They Cost?
Pricing determines total cost at scale. A 2x price difference compounds quickly at millions of requests per day.
Pricing Comparison (May 2026)
Cost Per 1M Typical Requests
Assuming average request: 2K input tokens, 500 output tokens:
Gemini 3.5 Flash is 60% cheaper than Claude Sonnet for equivalent workloads. At enterprise scale (100M+ requests/month), this translates to tens of thousands in monthly savings.
Which Model Handles Tool Calling Best?
For agentic applications, tool calling reliability determines whether your agent completes tasks or enters infinite retry loops.
Tool Calling Benchmark
We tested each model on 200 function-calling scenarios with increasing complexity:
GPT-4.1 Mini leads on deterministic, schema-compliant tool calling — the model almost never produces malformed JSON or selects the wrong function. Claude Sonnet 4.6 wins when tool calling requires reasoning about which tool to use based on complex context.
Tool Calling Code Example
How Do They Handle Long Context?
All three models advertise 1M token context windows. But advertised capacity and effective retrieval accuracy are different things.
Needle-in-a-Haystack Results
We inserted target facts at various positions within contexts of increasing length:
Claude Sonnet 4.6 maintains remarkably consistent retrieval accuracy even at 1M tokens — a 6-point drop vs 21 points for Gemini 3.5 Flash. If your application requires faithful processing of very long documents (legal contracts, full codebases, research paper collections), Claude's long-context implementation is meaningfully superior.
For most production use cases under 128K tokens, all three models perform equivalently.
What About Multimodal Capabilities?
All three models accept image inputs. Gemini 3.5 Flash additionally supports native audio and video input.
Vision Benchmark
Gemini 3.5 Flash leads on OCR and adds exclusive video/audio support. Claude Sonnet 4.6 excels at understanding complex visual relationships — charts, UI layouts, and multi-image comparisons.
Which Model Should You Choose?
Choose Gemini 3.5 Flash When:
- Latency is your primary constraint — sub-200ms TTFT enables real-time chat and streaming UIs
- Cost dominates at scale — 60% cheaper than alternatives at 100M+ requests/month
- You need multimodal breadth — video and audio input without separate transcription pipelines
- Classification and routing tasks — high accuracy on simple extraction at maximum speed
- Batch processing large volumes — throughput advantage compounds for background jobs
Choose Claude Sonnet 4.6 When:
- Reasoning quality is non-negotiable — code generation, complex analysis, multi-step problems
- Long context faithfulness matters — legal, research, or codebase understanding at 500K+ tokens
- Creative and nuanced output — marketing copy, documentation, user-facing content
- Agentic reasoning chains — tool selection that requires understanding complex intent
- You need extended thinking — problems that benefit from chain-of-thought reasoning
Choose GPT-4.1 Mini When:
- Structured output reliability is critical — JSON schema compliance, function calling, data extraction
- You're building agentic pipelines — lowest retry rates reduce total completion time
- Instruction following precision — the model does exactly what you specify, no more
- You're already in the OpenAI ecosystem — Assistants API, fine-tuning, batch API integration
- Parallel tool calling — highest accuracy when invoking multiple tools simultaneously
How to Migrate Between Models
Switching between these models requires minimal code changes but careful prompt adjustment:
Prompt Adaptation Tips
What's the Production Architecture?
Most production systems in 2026 don't use a single model. The optimal architecture routes requests based on complexity, cost sensitivity, and latency requirements:
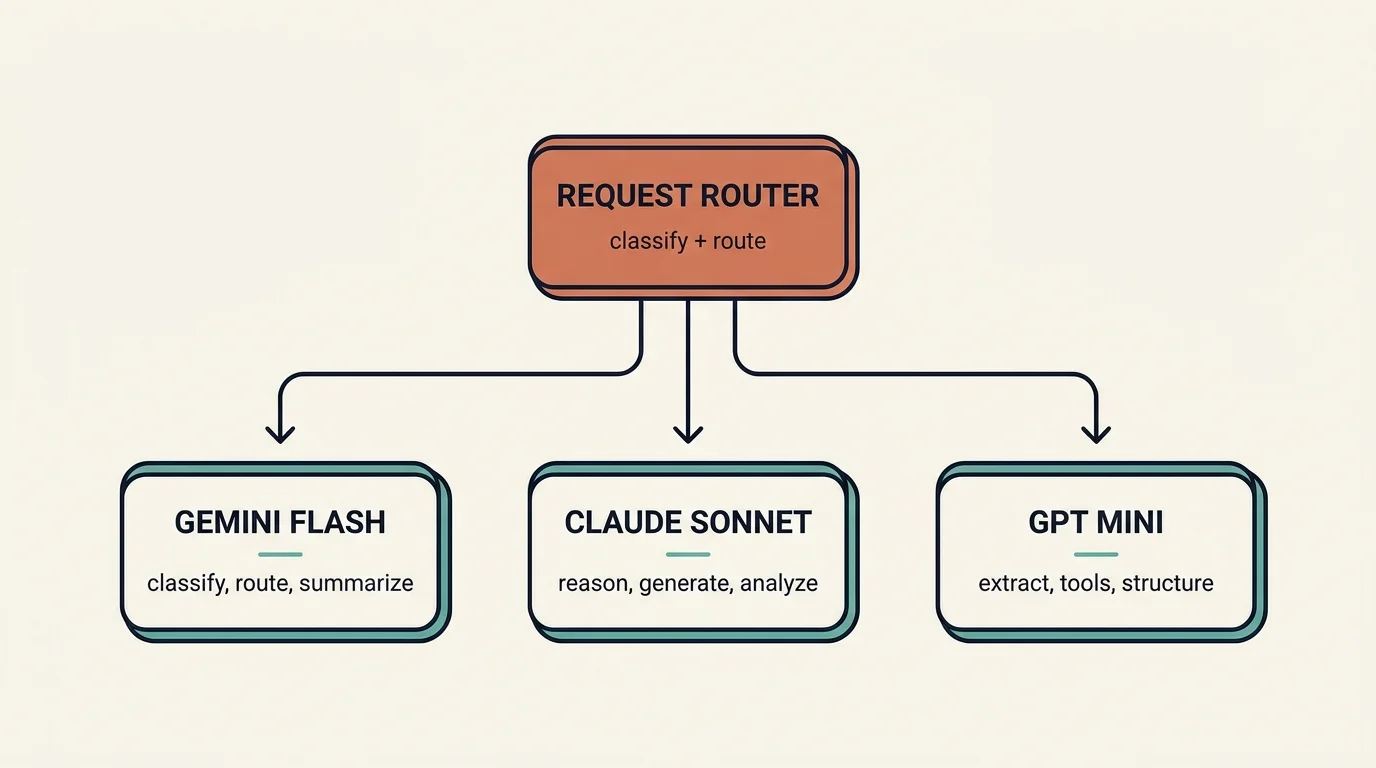
A request router classifies each incoming request by complexity, task type, and latency requirement, then dispatches it to the cheapest model that can handle it:
- Gemini 3.5 Flash — classify, route, summarize, stream
- Claude Sonnet 4.6 — reason, generate, analyze, create
- GPT-4.1 Mini — extract, call tools, structure, validate
This multi-model architecture reduces cost by 40-60% compared to routing everything through a single premium model, while maintaining quality ceilings on tasks that need them.
How Will This Tier Evolve?
The speed-tier competitive landscape changes quarterly. Key trends to watch:
- Convergence on price — all three providers have cut speed-tier pricing 3x in the past year; expect continued drops as inference hardware improves
- Native tool calling standards — MCP (Model Context Protocol) adoption means tool definitions become portable across providers
- Speculative decoding — Gemini's speed advantage partially stems from aggressive speculative decoding; expect others to close the throughput gap
- Cached context pricing — all three now offer 75% discounts on cached input tokens, making repetitive agentic loops dramatically cheaper
- Regional availability — Gemini leads on global edge deployment; Claude and GPT are expanding beyond US/EU data centers
FAQ
Which model is cheapest for high-volume production workloads?
Gemini 3.5 Flash at $0.15/M input and $0.60/M output tokens is the cheapest option — 60% less than Claude Sonnet 4.6 and 50% less than GPT-4.1 Mini. With cached input pricing at $0.0375/M, repetitive workloads (like agentic loops with consistent system prompts) become extremely affordable at scale.
Can Claude Sonnet 4.6 match Gemini 3.5 Flash speed with prompt caching?
Prompt caching reduces Claude's time-to-first-token by 40-60% for repeated prefixes, narrowing the TTFT gap from 2.1x to approximately 1.3x. However, output throughput (tokens/second) remains unchanged by caching — Gemini 3.5 Flash still generates tokens 2.1x faster regardless of cache state.
Which model should I use for building AI agents with tool calling?
GPT-4.1 Mini for pure tool-calling reliability (98.7% structured output compliance, lowest retry rates). Claude Sonnet 4.6 if your agent needs to reason about which tools to use in ambiguous situations. Gemini 3.5 Flash if your agent makes many simple tool calls where speed matters more than handling edge cases.
Is it worth using multiple models in the same application?
Yes — multi-model routing reduces cost 40-60% while maintaining quality. Use Gemini 3.5 Flash for classification and simple tasks (80% of requests), Claude Sonnet 4.6 for complex reasoning (15%), and GPT-4.1 Mini for structured extraction (5%). The router itself can be a simple rule-based system or a fine-tuned classifier.
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
GPT Image 2 vs Gemini 3 Pro Benchmark 2026
Compare GPT Image 2 vs Gemini 3 Pro across 8 categories. Gemini is 4x faster, GPT has better detail. Full results with outputs.
AI Engineering, Multimodal AIAgentCore vs LangChain: 2026 Framework Guide
Compare AgentCore and LangChain for AI agents. Architecture, pricing, and deployment trade-offs explained with code.
AI Engineering, Agent FrameworksSmall Tool Calling Models: Edge AI Guide 2026
Compare Needle 26M, FunctionGemma 270M, Qwen 0.6B, and Granite 350M for on-device tool calling. Architecture and benchmarks.
AI Engineering, Edge AI