Small Tool Calling Models: Edge AI Guide 2026
Compare Needle 26M, FunctionGemma 270M, Qwen 0.6B, and Granite 350M for on-device tool calling. Architecture and benchmarks.

TL;DR: Needle is a 26M-parameter model distilled from Gemini 3.1 that outperforms models 10-25x its size on single-shot function calling, decoding at 1,200 tokens/second on edge hardware. For on-device AI agents that need to route user commands to the right tool with correct arguments — smartwatches, phones, glasses — specialized tiny models now beat general-purpose small LLMs by trading conversational breadth for tool-calling precision.
Key Takeaways
- Needle (26M params) beats FunctionGemma (270M), Qwen (600M), Granite (350M), and LFM2.5 (350M) on single-shot function calling by using a no-FFN encoder architecture distilled from Gemini 3.1 on 200B tokens.
- Edge tool calling requires sub-100ms latency and under 50MB memory — only models below 500M parameters can run on consumer devices without cloud connectivity.
- The distillation approach (large teacher model → tiny specialized student) produces better tool-calling accuracy than training small models from scratch on the same data.
- Grouped Query Attention with tied embeddings and no feed-forward layers in the encoder reduces Needle's parameter count by 60% compared to a standard transformer of equivalent attention capacity.
- Single-shot function calling (one user query → one tool invocation) is a fundamentally different task from multi-turn agentic reasoning — models optimized for one often fail at the other.
- Fine-tuning these models on your specific tool schemas takes under 1 hour and dramatically improves accuracy for domain-specific deployments.
Why Small Models for Tool Calling?
Every AI agent framework — LangChain, AgentCore, CrewAI — sends tool-calling requests to large cloud models. GPT-4o, Claude Sonnet, Gemini Pro all handle function calling excellently, but they require network round-trips of 500-2000ms, cost $3-15 per million tokens, and expose user data to third-party APIs. For the next wave of AI agents running on personal devices, this architecture breaks down.
Consider a smartwatch that needs to parse "set a timer for 8 minutes" into {"name": "set_timer", "arguments": {"duration_minutes": 8}}. The latency budget is 50ms. The memory budget is 30MB. The privacy requirement is absolute — no data leaves the device. No 70B parameter model fits this constraint. No cloud API meets this latency.
This gap created demand for tiny models specialized exclusively for tool calling — models that sacrifice general knowledge and conversational ability to achieve near-perfect accuracy on a narrow task: given a user query and a set of available tools, select the correct tool and generate valid arguments.
In early 2026, five models compete in this space, each with different architectural bets.
How Does Tool Calling Actually Work at the Model Level?
Before comparing models, it helps to understand what "tool calling" means computationally. The model receives a structured prompt containing:
- A user query (natural language)
- A tool schema (JSON describing available functions, their parameters, and types)
- An instruction to output a structured tool invocation
The model must:
- Understand the user's intent
- Match it to the correct tool from available options
- Extract parameter values from the query
- Generate valid JSON with correct types
This is fundamentally a structured generation problem, not a conversational one. The model doesn't need world knowledge, reasoning chains, or multi-turn context. It needs pattern matching between natural language intents and function signatures, plus reliable JSON generation.
This insight is why specialized small models can beat general-purpose LLMs 25x their size — they allocate all their capacity to the specific computation needed, rather than spreading parameters across encyclopedic knowledge and general reasoning.
The Contenders: Architecture Comparison
The size difference is striking. Needle is 10x smaller than its nearest competitor and 23x smaller than Qwen. Yet it claims superior single-shot function calling accuracy. How?
Deep Dive: Needle's Architecture
Needle uses what Cactus Compute calls a "Simple Attention Network" — an encoder-decoder architecture with unusual design choices optimized specifically for the function-calling task.
Encoder (12 layers)
The critical design choice: no feed-forward network layers. In a standard transformer, each layer has a self-attention block followed by a 2-layer FFN (typically 4x the embedding dimension). The FFN acts as a key-value memory that stores factual knowledge learned during pre-training. By removing it entirely from the encoder, Needle makes an explicit architectural statement: the encoder doesn't need to store knowledge — it only needs to understand the structural relationship between tokens.
For tool calling, this makes sense. The encoder processes the user query and tool schemas. It doesn't need to know that Paris is the capital of France — it needs to understand that "weather in Paris" maps to the location parameter of get_weather. This is purely relational, not factual.
Decoder (8 layers)
The decoder includes cross-attention over encoder outputs and self-attention for autoregressive generation. It generates the structured JSON output token by token.
Grouped Query Attention (GQA)
Needle uses 8 attention heads with only 4 key-value heads — meaning KV heads are shared between pairs of query heads. This halves the KV cache memory during inference, critical for edge devices with limited RAM.
Tied Embeddings
The embedding matrix is shared between encoder input, decoder input, and output projection. With a vocabulary of only 8,192 tokens, this saves approximately 8M parameters (8192 × 512 × 2 matrices that would otherwise be separate).
Parameter Budget Breakdown
By eliminating FFN layers and using a tiny vocabulary, nearly all parameters go to attention — the component that actually matters for understanding query-tool relationships.
How Distillation from Gemini 3.1 Works
Needle wasn't trained from scratch on tool-calling examples. It was distilled from Gemini 3.1 in a two-phase process:
Phase 1: General Distillation (27 hours, 16 TPU v6e)
The 26M student model learns to predict the next token on 200 billion tokens, with Gemini 3.1's output logits as soft targets. This transfers general language understanding — syntax, semantics, common patterns — without requiring the student to have enough parameters to store all of Gemini's factual knowledge.
The key insight: distillation transfers capability (how to process language) more efficiently than knowledge (what facts are true). A 26M model can learn Gemini's linguistic computation patterns even though it can't store Gemini's world knowledge.
Phase 2: Function-Call Specialization (45 minutes)
The pre-trained model is then fine-tuned on 2 billion tokens of single-shot function-call data — pairs of (query + tools) → (tool invocation JSON). This phase narrows the model's general language ability into the specific structured generation task.
The brevity of Phase 2 (45 minutes vs 27 hours) suggests that Phase 1 does most of the heavy lifting — the model already knows how to process language; it just needs to learn the specific output format.
Practical Usage: Running Needle
Installation
Basic Function Calling
Fine-Tuning on Custom Tools
Interactive Playground
This launches a web UI where you can test queries against your tool schemas and iterate on fine-tuning — making it straightforward to validate accuracy before deploying to a device.
Performance: What the Numbers Mean
Inference Speed
On edge hardware, Needle completes a full tool-call generation in approximately 40ms — well within the 100ms latency budget required for responsive voice assistants.
Memory Footprint
At INT4 quantization, Needle fits in 13MB — small enough to run alongside other applications on a smartwatch with 512MB total RAM.
Accuracy (Single-Shot Function Calling)
Cactus Compute reports Needle beating all comparison models on single-shot tool calling. The critical nuance: this is specifically for single-shot scenarios where the model sees one query, a tool schema, and must produce one correct tool call. For multi-turn conversations where the model must maintain context, larger models still dominate.
This specialization trade-off is the central insight: Needle sacrifices general capability for extreme performance on a narrow task. It cannot hold a conversation. It cannot answer questions. It cannot reason about multi-step plans. It does one thing — map queries to tool calls — and does it better than models 25x its size.
When to Use Which Model
Use Needle (26M) when:
- Deploying on severely constrained hardware (watches, glasses, IoT sensors)
- Latency budget is under 50ms
- Tool set is fixed and well-defined (can be fine-tuned)
- Single-shot routing only (user command → one tool invocation)
- Privacy is critical — no data can leave the device
Use FunctionGemma (270M) when:
- Deploying on mobile devices with more headroom
- Need some conversational ability alongside tool calling
- Want Gemma ecosystem compatibility (quantization tools, deployment libraries)
- Multiple tool calls per query may be needed
Use Qwen2.5-Coder (600M) when:
- Tool calling is one feature among many (code generation, chat)
- Running on laptop/desktop with GPU
- Need multi-turn context and tool calling combined
- Cloud deployment is acceptable
Use Granite-FC (350M) when:
- Enterprise deployment with compliance requirements
- IBM ecosystem integration
- Need function calling with enterprise tool schemas (SAP, ServiceNow)
- Batch processing of structured requests
Use LFM2.5 (350M) when:
- Exploring state-space alternatives to pure transformers
- Extremely long tool schemas (state-space models handle long sequences efficiently)
- Research contexts comparing architectural approaches
Building an Edge AI Agent with Small Models
Here's a practical architecture for deploying small tool-calling models in production:
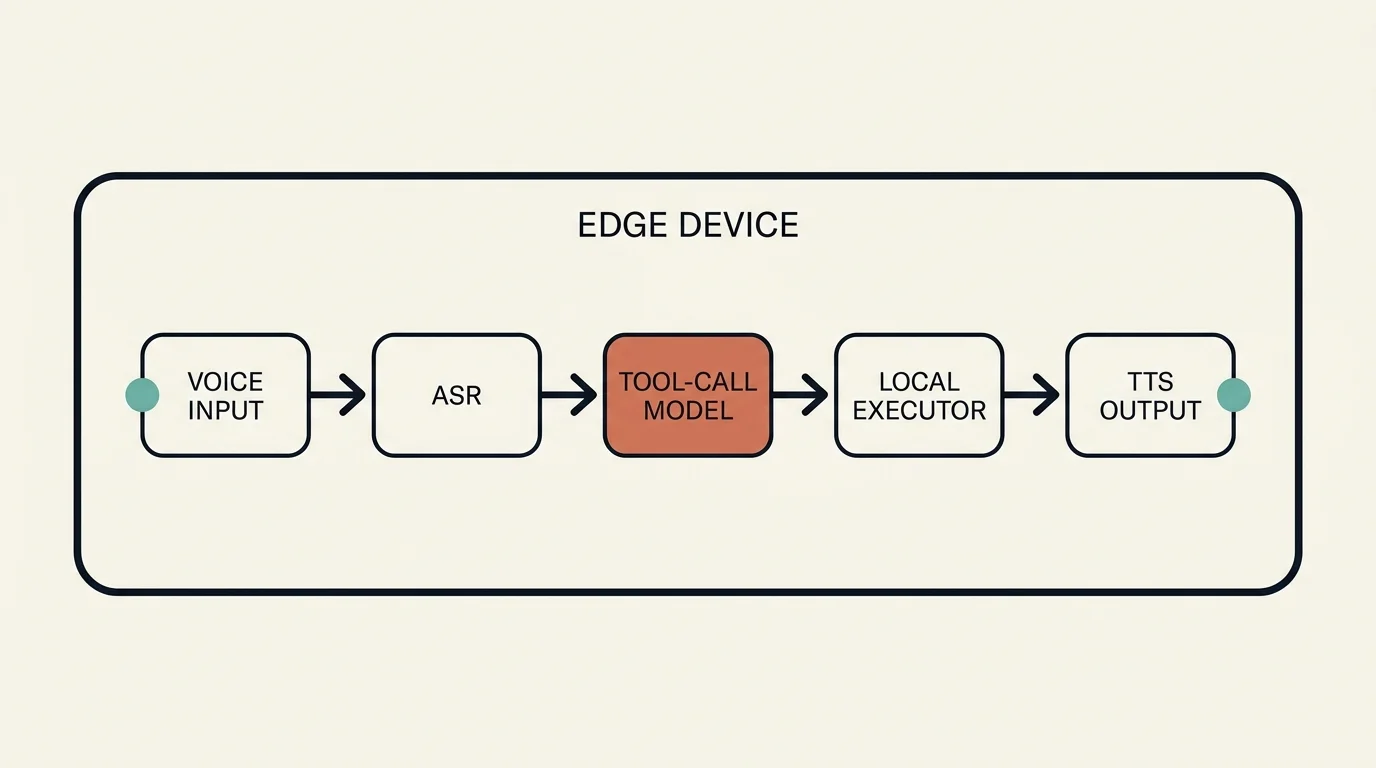
The whole pipeline runs on the edge device, no network round-trip: voice input is transcribed by a tiny ASR model (e.g. Whisper Tiny), the resulting text query plus a tool schema goes to a small tool-calling model (e.g. Needle, 26M params) that emits a tool call, a local executor runs it, and the response is spoken back out through text-to-speech.
The tool-calling model is one component in a pipeline. On a modern smartphone, this entire pipeline runs in under 200ms end-to-end:
- ASR (Whisper Tiny, 39M params): Speech → text (~80ms)
- Tool Router (Needle, 26M params): Text → tool call (~40ms)
- Execution: Run the function locally (~10ms)
- TTS (response generation): Text → speech (~70ms)
No cloud. No network latency. No API costs. No privacy concerns.
Handling Ambiguity
What happens when the user query doesn't clearly map to any tool? Small models need a fallback strategy:
This hybrid architecture uses the tiny model for the 80% of queries that map cleanly to tools, and falls back to a cloud model only when needed.
The Distillation Paradigm Shift
Needle represents a broader trend: instead of making small models good at everything (the Phi/Gemma approach), make them perfect at one thing through targeted distillation. This has implications beyond tool calling:
- Classification models: Distill a large model's intent classification into a 10M-param specialist
- Structured extraction: Distill entity recognition for specific domains into tiny models
- Routing: Use a 5M-param model to route queries to the appropriate larger model or API
The common thread is that many "AI tasks" in production systems are actually narrow pattern-matching problems disguised as general language understanding. A 26M model with the right architecture and training data can handle them better than a 70B generalist.
Limitations and Open Questions
What small models can't do:
- Multi-step reasoning: "Book me a flight, then add it to my calendar" requires planning that 26M parameters can't support
- Ambiguous queries: "Help me with that thing from yesterday" needs conversational memory
- Novel tool schemas: Without fine-tuning, accuracy drops significantly on unseen tool formats
- Error recovery: If a tool call fails, small models can't reason about what went wrong
Open research questions:
- How small can you go? Is 26M the floor, or can 5M-param models handle fixed tool schemas?
- Continuous learning: Can models update tool schemas without full retraining?
- Multi-modal inputs: Can vision-language models at 50M params handle "take a photo and file this receipt"?
- Verification: How do you validate tool-call correctness without running the actual function?
FAQ
What is the difference between tool calling and function calling in AI models?
Tool calling and function calling refer to the same capability — an AI model selecting a specific function and generating structured arguments based on a natural language query. "Function calling" was the original term used by OpenAI's API, while "tool calling" became the broader industry standard encompassing MCP tools, API endpoints, and local functions. Both describe the model's ability to output structured JSON that invokes external capabilities rather than generating free-text responses.
Can Needle replace GPT-4o for tool calling in production?
Needle replaces GPT-4o only for single-shot tool routing on edge devices with fixed tool schemas. If your application needs multi-turn conversations, complex reasoning about which tools to chain together, or handles hundreds of different tool schemas dynamically, large cloud models remain necessary. Needle excels when latency, privacy, and cost constraints make cloud models impractical and the tool-calling pattern is predictable.
How much fine-tuning data is needed for accurate tool calling on custom schemas?
Cactus Compute's pipeline generates 10,000+ synthetic examples per tool set, which takes approximately 45 minutes to fine-tune. In practice, 1,000-5,000 high-quality examples per tool typically achieve 95%+ accuracy on well-defined schemas. The data should cover variations in phrasing, parameter edge cases (missing optional params, multiple valid phrasings), and negative examples (queries that don't match any tool).
What hardware can run a 26M parameter model in production?
At INT4 quantization (13MB), Needle runs on virtually any modern processor including smartphone CPUs (Snapdragon 8 Gen 3, Apple A17), smartwatch chips (Snapdragon W5+), and embedded systems (Raspberry Pi 5, ESP32-S3 with PSRAM). The model requires no GPU — pure CPU inference at 1,200 tokens/second is fast enough for real-time tool calling. Any device with 50MB of free RAM can run Needle alongside other applications.
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
6 Best AI Agent Frameworks 2026: LangChain vs AgentCore vs CrewAI
Agent frameworks 2026 compared: LangChain leads ecosystem with 95K stars, AgentCore offers managed AWS runtime, LangGraph excels at complex workflows. Production benchmarks included.
AI Agent Development, Framework ComparisonContext Engineering for AI Agents: 6 Techniques That Cut Our Costs 10x
One misplaced timestamp invalidated our entire KV cache and 10x'd our bill. Here are 6 context engineering patterns from Manus and production agent teams that prevent exactly this -- with code examples.
AI Engineering, Agent FrameworksAI Coding Agent Architecture: Agent Loop Deep Dive
Explore how Claude Code, Cursor, Aider, and Cline work under the hood. Agent loops, tool dispatch, and edit strategies explained.
AI Engineering, Agent Frameworks