AWS AI-DLC: The Agentic Dev Lifecycle That Works Everywhere
Master AWS AI-DLC for disciplined AI pair-programming. Works across Kiro, Cursor, Claude Code, and Copilot with zero lock-in.
AWS AI-DLC: The Agentic Development Lifecycle That Works Across Every IDE
TL;DR: AI-DLC (AI-Driven Development Life Cycle) is AWS's answer to "vibes-based" AI coding. It's a rule-based steering system — not a tool or library — that transforms AI pair-programming from ad-hoc prompting into a structured, three-phase lifecycle (Inception → Construction → Operations). It runs on any AI coding agent that supports rule files: Kiro, Amazon Q, Cursor, Claude Code, Copilot, and more. The rules are the same everywhere; only the file location changes. Your workflow state persists in plain workspace files, so you can switch IDEs mid-project without losing progress.
Key Takeaways
- AI-DLC is a methodology delivered as rule files — it works on 7+ coding assistants because it's agent/IDE/model agnostic. The rules file content is identical across platforms; only the path differs (`.kiro/steering/`, `.cursor/rules/`, `CLAUDE.md`, etc.).
- The three-phase architecture (Inception, Construction, Operations) is adaptive — simple bug fixes skip most stages, while complex system migrations get full treatment with per-unit design loops.
- Reverse Engineering automatically scans existing codebases to build context artifacts that feed every subsequent stage. Without it, AI coding agents duplicate services, break patterns, and ignore existing architecture.
- The per-unit construction loop means complex projects get decomposed into parallelizable work packages, each with its own functional design → NFR → code generation → test cycle.
- An extension system lets enterprises layer blocking constraints (HIPAA compliance, internal SDK rules, security baselines) that halt the workflow on violations — not just warnings, actual blockers.
- Session continuity works via plain workspace files (`aidlc-docs/aidlc-state.md`). Start in Cursor on Monday, switch to Claude Code on Wednesday — the AI reads the same state file and resumes exactly where you left off.
The Problem This Solves
We've all been there. You open your AI coding agent — Claude Code, Cursor, Copilot, whatever — and type "build a user API." The agent immediately starts writing code. It picks REST (you wanted GraphQL). It uses Express (your team uses Fastify). It creates a new auth service (you already have one). It ignores your company's error code standards.
The fundamental issue isn't the AI's coding ability. It's that nobody told the AI to ask questions first.
AI-DLC fixes this by inserting a structured questioning and planning phase before any code is written. It's the difference between a junior dev who immediately starts typing and a senior architect who says "wait — let me understand the requirements, check the existing system, and propose an approach before we write a single line."
Core Philosophy
Before diving into the mechanics, here's what drives the design:
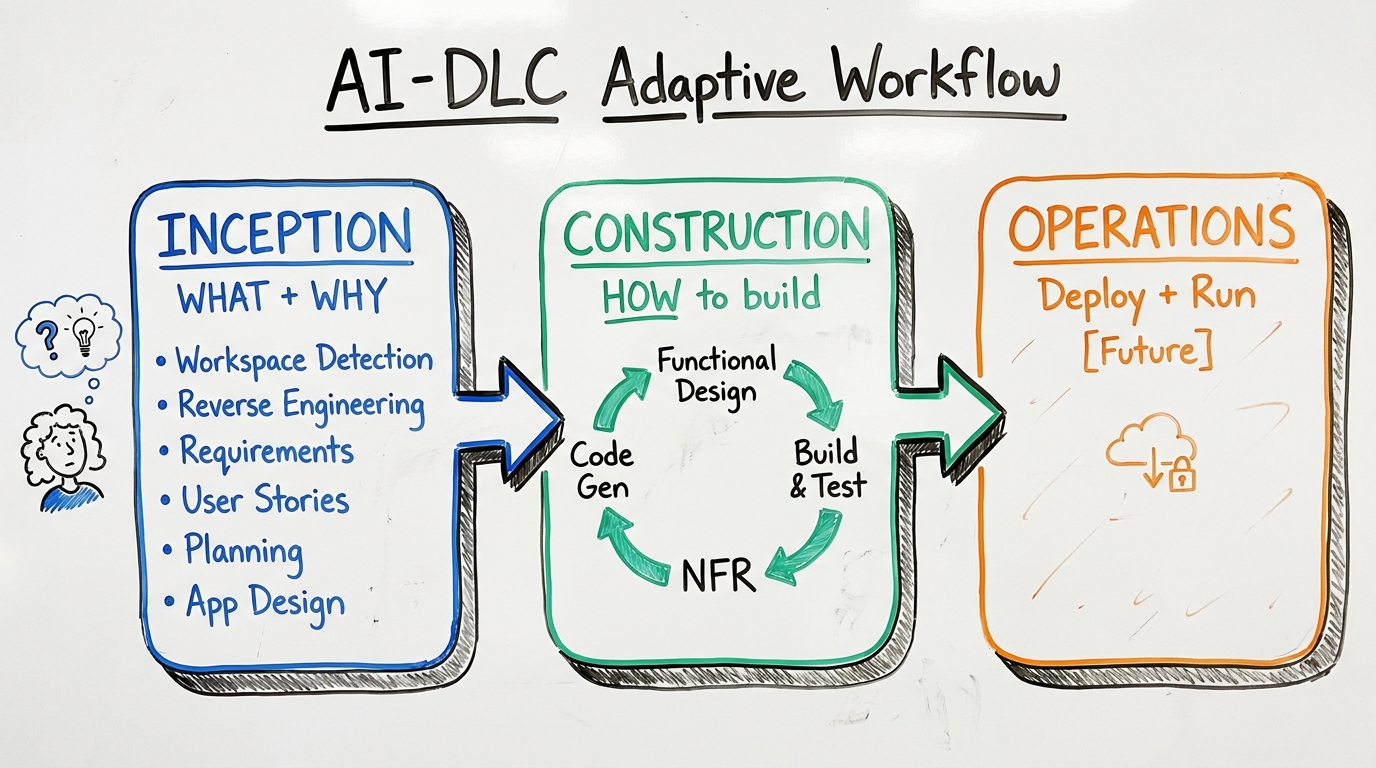
The Three-Phase Architecture

AI-DLC structures development into three phases, each answering a different question:
Inception — WHAT to build and WHY. This is where requirements get clarified, existing code gets understood, and work gets planned. Contains six stages: Workspace Detection, Reverse Engineering, Requirements Analysis, User Stories, Workflow Planning, and Application Design. For a simple bug fix, most of these get skipped. For a new platform, they all fire.
Construction — HOW to build it. This is the per-unit loop where each piece of the system gets designed, coded, and tested independently. Contains: Functional Design, NFR Requirements, NFR Design, Infrastructure Design, Code Generation (plan + execute), and Build & Test.
Operations — How to DEPLOY and RUN. Currently a placeholder in the framework — future phases for deployment, monitoring, incident response, and maintenance.
Adaptive Depth
The framework uses three depth levels that scale documentation rigor to problem complexity:
Key insight: stage selection is binary (execute or skip), but detail within executed stages is adaptive. All mandatory artifacts are always produced; only their depth of content varies.
Deep Dive: Reverse Engineering — Why It Matters
When you ask an AI to "add a payment feature" to an existing 50-file codebase, the AI needs to understand the current architecture before it can make intelligent additions. Without reverse engineering, the AI might create duplicate services, ignore existing patterns, or break established conventions.
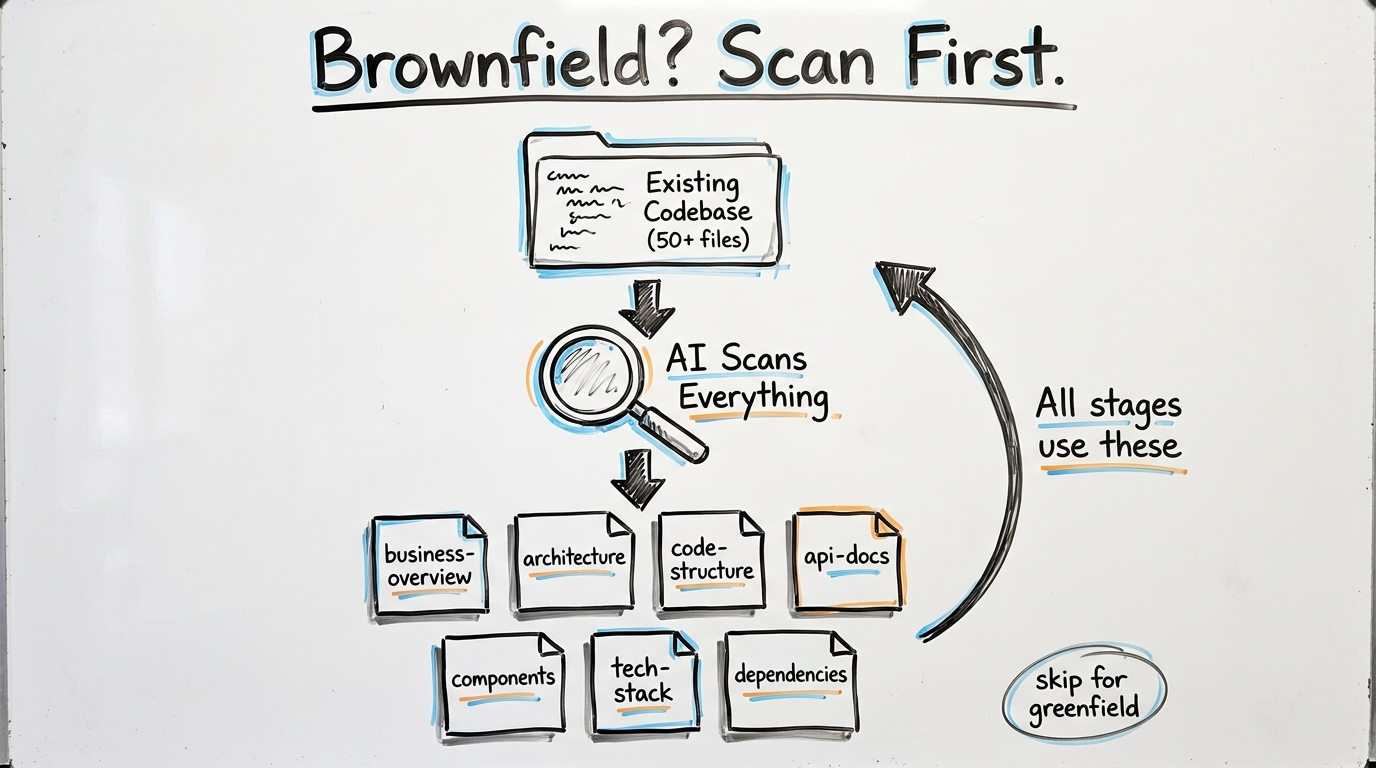
When it triggers: Only for "brownfield" projects (existing code detected in workspace). Skipped entirely for greenfield (empty) projects.
What it produces — imagine you have an existing e-commerce backend:
Why this matters: Every subsequent stage (Requirements, Design, Code Generation) loads these artifacts. When the AI generates code later, it knows which files to modify vs. create new, which patterns to follow, which services already exist, and what the dependency graph looks like.
Staleness detection: If you resume a project months later and the codebase has changed significantly, Workspace Detection compares artifact timestamps against the latest code modifications. Stale artifacts trigger a re-run.
Application Design → Units Generation
This is one of the subtler relationships in AI-DLC, and it confused me at first. They sound similar but serve completely different purposes.
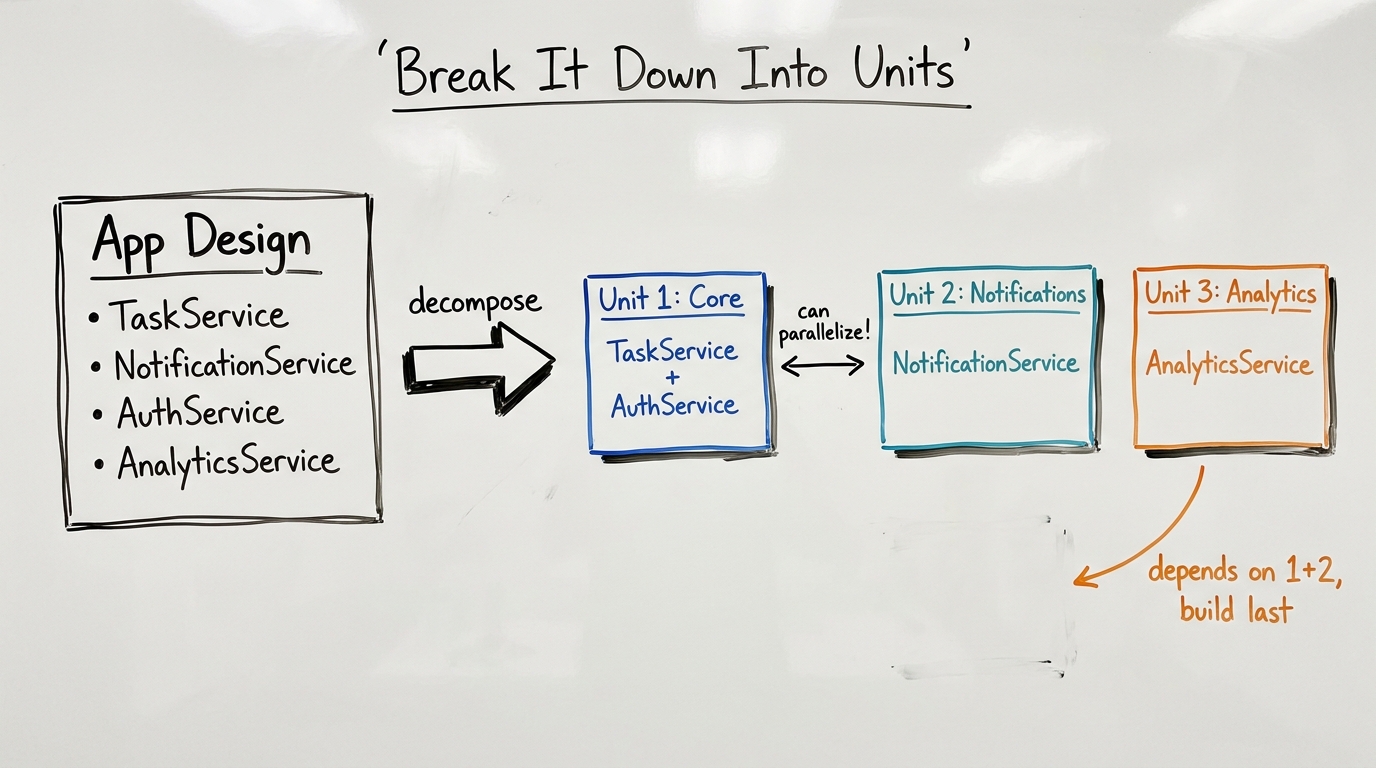
Application Design = "What are the building blocks?" It identifies high-level components, their responsibilities, and how they interact. Think of it as drawing the boxes on an architecture whiteboard.
For a "Task Management SaaS" project, Application Design would produce:
Units Generation = "How do we break this into parallelizable work packages?" It takes the Application Design output and groups it into units of work — logical scopes that can be developed independently.
The relationship is directional: Application Design is about architecture (what exists, how it connects). Units Generation is about development strategy (what to build first, what can parallelize). Simple projects may need Application Design but skip Units Generation (single unit). Complex projects need both.
What Is a "Unit of Work"?
A unit of work is a logical grouping of related stories/features that can be designed, coded, and tested as a cohesive package. It is NOT a microservice, a file, or a sprint. It's the smallest chunk of the system that makes sense to hand to one developer (or one AI session) and say "build this completely."
How it maps to architecture types:
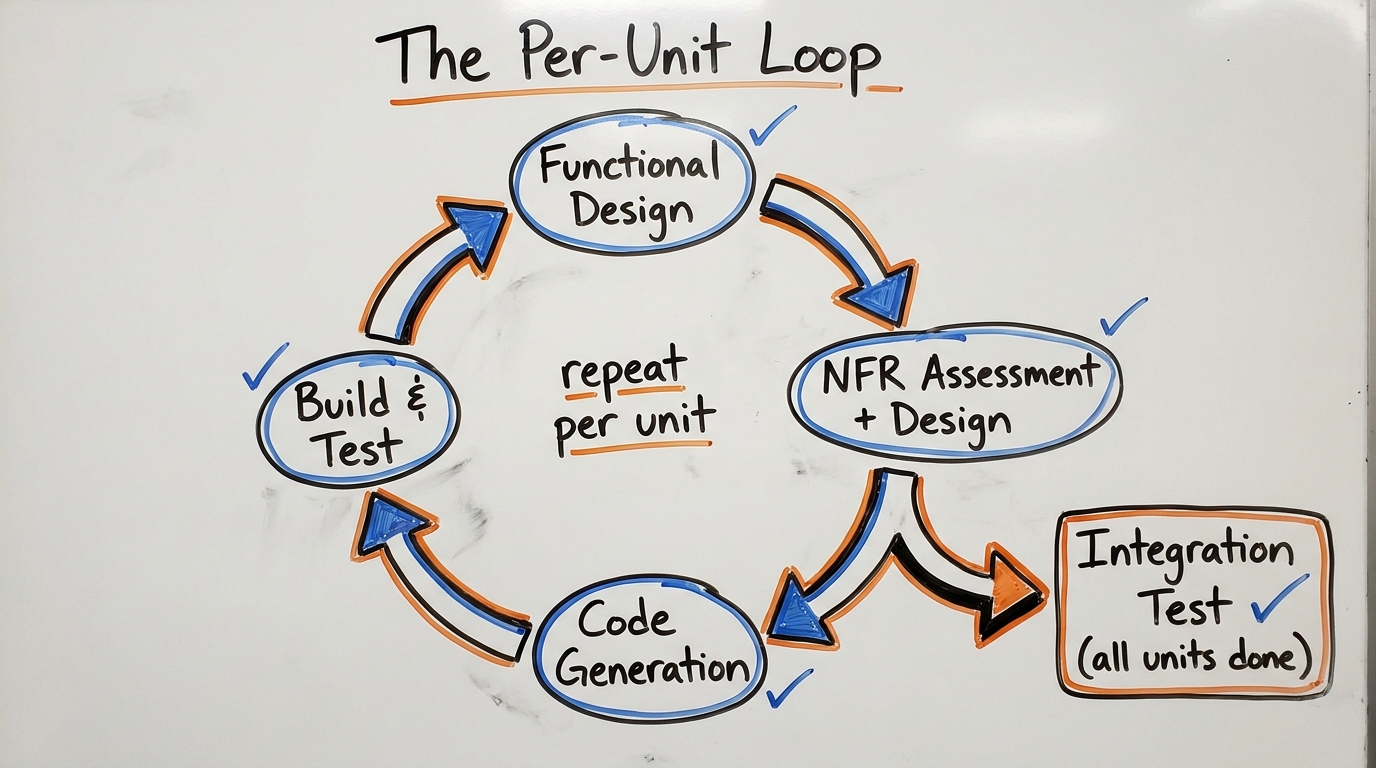
The Per-Unit Construction Loop
Each unit goes through its own full design-and-build cycle:
NFR — Non-Functional Requirements Explained
NFR = the qualities and constraints of a system that are NOT about what it does, but HOW WELL it does it.
AI-DLC has two NFR stages per unit:
NFR Requirements Assessment asks: What are your scalability expectations? Performance benchmarks? Security/compliance standards? Tech stack preferences?
NFR Design takes those answers and produces concrete architectural patterns, technology selections with justification, and infrastructure requirements.
The Extension System — Enterprise Rules That Actually Block
Most linting and compliance tools generate warnings that developers ignore. AI-DLC extensions are different — they're blocking constraints. If code violates a rule, the workflow halts.
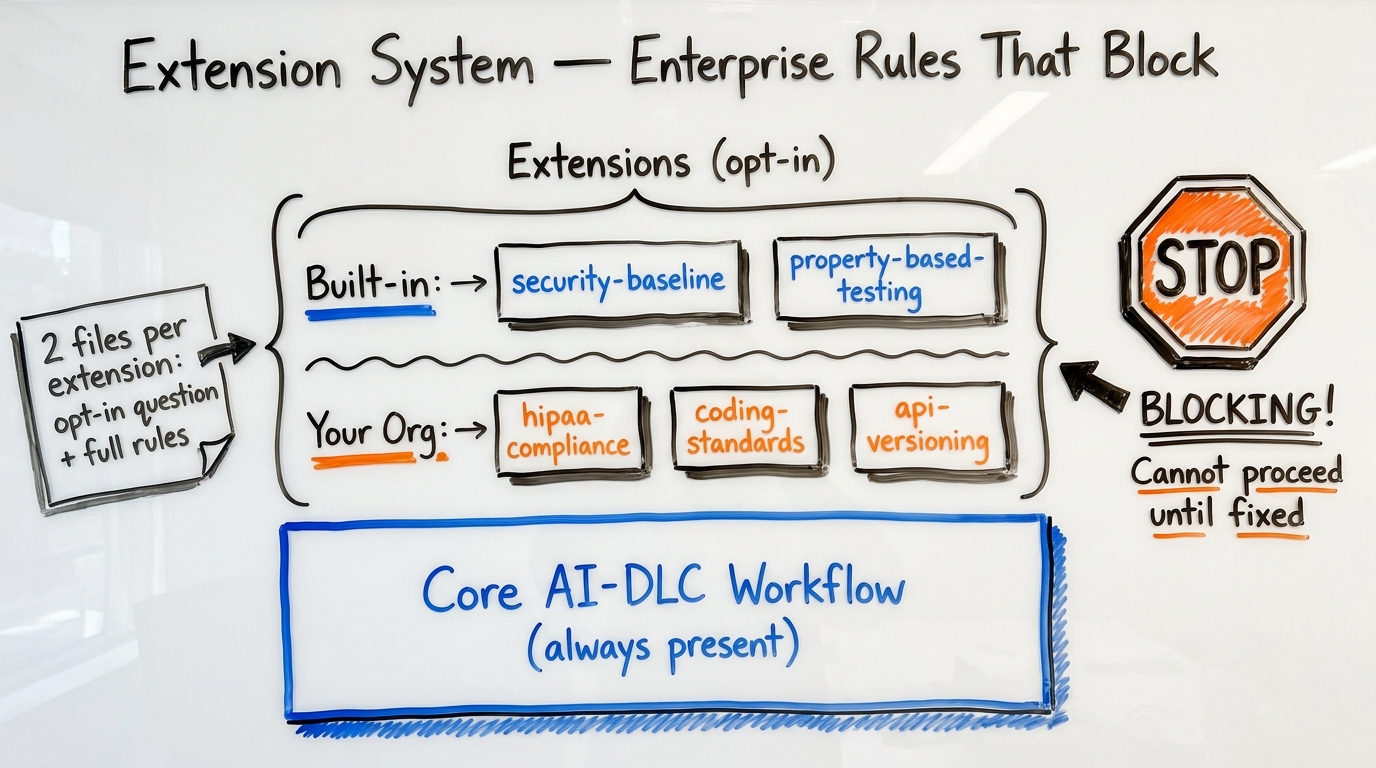
The Two-File Convention
Each extension consists of exactly two files:
Opt-in file (lightweight, always loaded):
Rules file (heavy, loaded only on opt-in):
Enforcement Behavior
What Organizations Can Build
Key design decisions: extensions without an opt-in file are always enforced (no user choice). N/A rules are logged but not blocking. Extension compliance is summarized at each stage completion.
The Two-Layer File System — The Architectural Insight
This is the thing that clicked for me after staring at the repo for a while. AI-DLC uses a two-layer file system where the layers serve completely different purposes:
Layer 1 — Rule Files (HOW the AI should behave): These are STATIC. They don't change during workflow execution. They're loaded by the platform's native rules mechanism:
Layer 2 — Workflow Artifacts (state generated DURING execution): These are DYNAMIC. Created/updated as the workflow progresses. They live in aidlc-docs/ which is a UNIVERSAL location for ALL platforms:
The analogy: Rule files = a recipe book (instructions on how to cook). aidlc-docs/ = the kitchen (where actual cooking happens and meals are stored). The recipe book tells you to "check the oven temperature" — the oven is separate from the recipe book.
Session Continuity — How It Actually Works Across Platforms
AI coding assistants don't remember previous conversations. Each new session starts with a blank context. AI-DLC's solution: use workspace files as persistent memory that survives session boundaries.
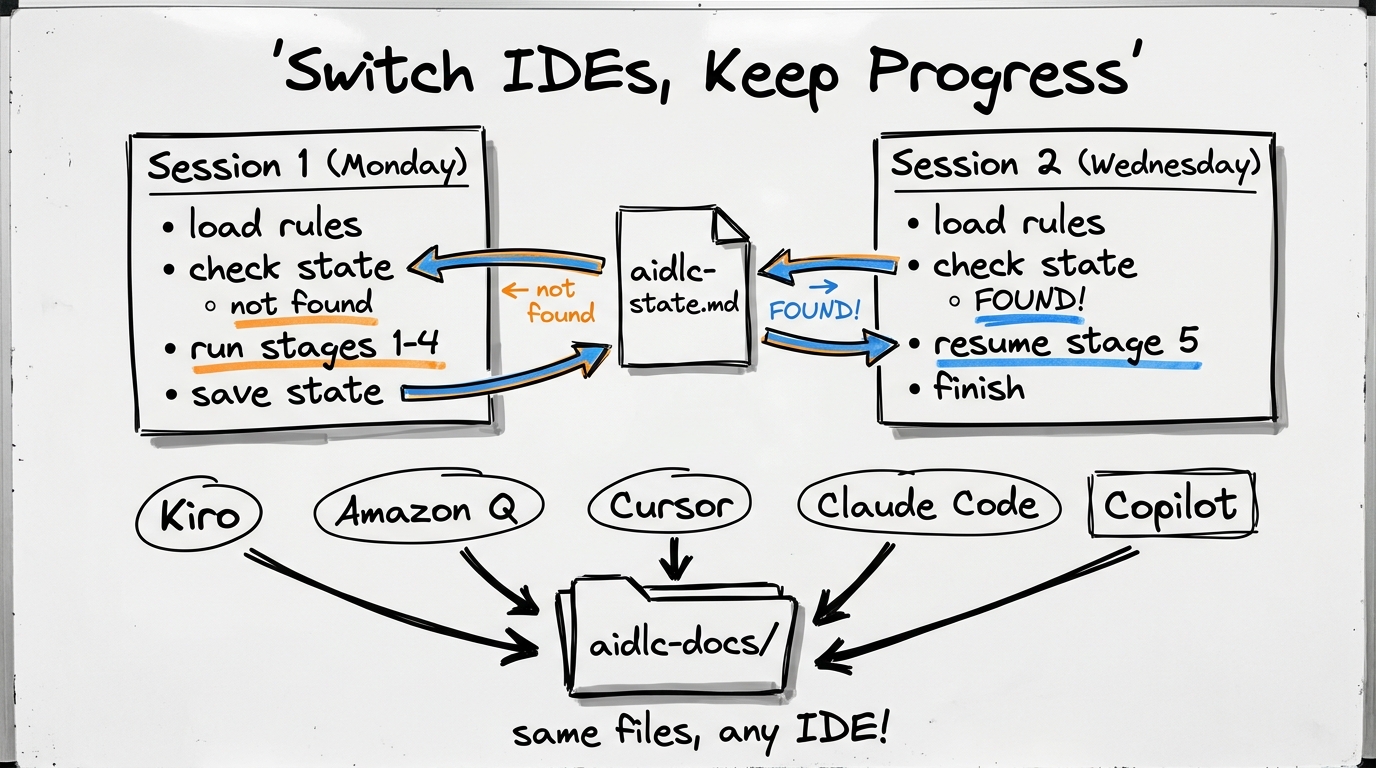
The Continuity Mechanism Step-by-Step
- New session starts → Platform loads rule file (core-workflow.md)
- Rule file instructs: "Run Workspace Detection → check for `aidlc-docs/aidlc-state.md`"
- If state file exists → AI reads it and finds:
- AI loads previous artifacts (requirements, designs, plans from `aidlc-docs/`)
- AI presents "Welcome Back" prompt with options to continue or review
- Work continues seamlessly from where it left off
Why This Works Across ALL Platforms
The genius of the approach:
The rule file's content is identical regardless of platform — only its location differs. You could switch IDEs mid-project: start with Cursor on Day 1 → generates aidlc-docs/. Switch to Claude Code on Day 5 → reads same aidlc-docs/, resumes from state.
Platform-Specific Enhancements
Some platforms offer additional session persistence beyond AI-DLC's file-based approach:
Important limitation: AI context windows are finite. Even when resuming, if the project has 20+ artifacts, the AI must selectively load what's relevant. AI-DLC handles this with "Smart Context Loading by Stage": early stages load only workspace analysis; design stages load requirements + stories + architecture; code stages load ALL artifacts + existing code.
The Human Approval Gate Pattern
Every stage follows: Generate → Present → Wait → Log
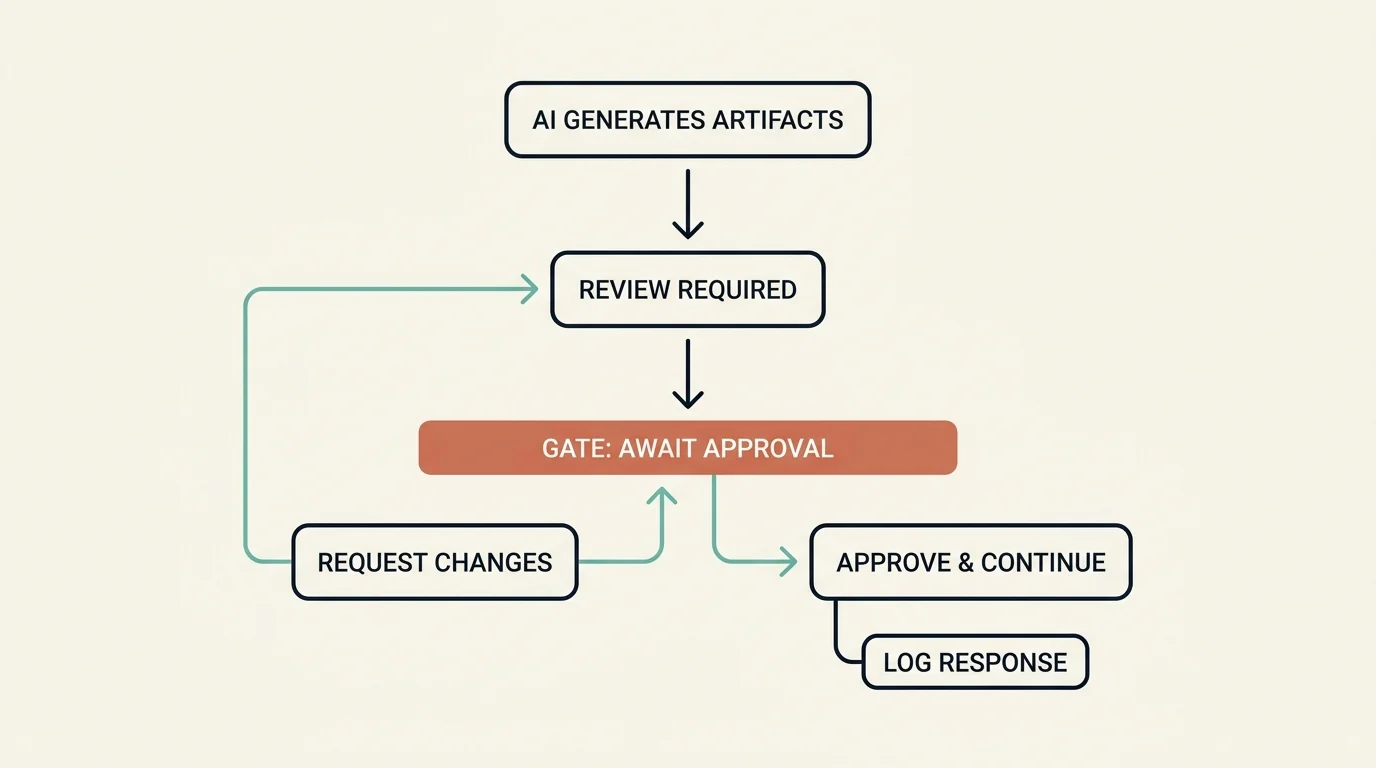
The AI generates artifacts and presents a completion message ("review required," with the choice to request changes or approve & continue). Then a hard gate blocks all forward progress until explicit approval: requesting changes loops back to review, while approval continues the workflow. Either way, the user's complete raw response is logged with an ISO 8601 timestamp.
This creates a complete audit trail. For regulated industries, you can trace exactly why a particular architectural decision was made, who approved it, and what context was available.
Anti-Overconfidence — My Favorite Design Choice
AI-DLC explicitly prevents the common AI problem of "assuming instead of asking":
Red flags the AI must detect in user answers:
- "depends" → follow up: "What does it depend on? Define the criteria"
- "mix of A and B" → follow up: "When do you use A vs B specifically?"
- "not sure" → follow up: "What information would help you decide?"
- "standard" → follow up: "Define 'standard' in your context"
What Makes This Different — The 10 Key Differentiators
- Agent-agnostic rule files — same methodology across 7+ coding assistants
- Adaptive intelligence — complexity drives depth, not rigid templates
- Anti-overconfidence by design — mandatory questioning and ambiguity resolution
- Full audit trail — every interaction logged with timestamps in `audit.md`
- Extension system — enterprises layer their own security, compliance, coding rules
- Session continuity via files — `aidlc-state.md` enables cross-session resume on any platform
- Separation of concerns — code at project root, docs in `aidlc-docs/`, rules in platform location
- Two-part stage pattern — plan approval before execution prevents wasted effort
- Per-unit loop — complex systems decomposed and built incrementally
- Blocking constraints — enabled extensions halt progress on non-compliance
Who Should Use This
AI-DLC is most valuable when:
- Your team uses AI coding agents daily and wants consistency
- You work on brownfield codebases where context matters
- You need audit trails for compliance or governance
- You want to switch between IDEs without losing workflow state
- You're building complex systems that need decomposition before coding
It's probably overkill for solo side projects or quick prototypes. The adaptive depth system mitigates this, but there's inherent overhead in the questioning phase. The extension system makes it particularly powerful for enterprises — you can encode your entire internal development playbook as blocking rules.
FAQ
Is AI-DLC a tool I need to install?
No. AI-DLC is a set of rule files (markdown documents) that you place in your project's rule directory. There's no CLI, no npm package, no binary. Your existing AI coding agent reads the rules and follows the methodology. It works on Kiro, Amazon Q, Cursor, Claude Code, Copilot, and any other agent that supports instruction/rule files.
Can I use AI-DLC with Claude Code and its CLAUDE.md?
Yes — Claude Code is one of the supported platforms. You either include the AI-DLC rules directly in your CLAUDE.md file or reference them via include paths. Claude Code's --continue flag provides additional session continuity on top of AI-DLC's file-based state system. The auto-memory feature also learns your preferences across projects.
What happens if I skip Inception and go straight to coding?
The framework is adaptive — for truly simple tasks, the AI will propose a minimal path. But force-skipping on a complex task means you lose reverse engineering context, requirements clarification, and architectural planning. The common failure mode is the AI duplicating existing services or breaking patterns because it never scanned the codebase.
How do AI-DLC extensions differ from regular linting rules?
Two key differences: scope and enforcement. Linting rules check syntax and style at the file level. AI-DLC extensions operate at the architecture level — "all APIs must be versioned," "every data model needs PHI classification," "minimum 3 replicas for stateful services." And they're blocking: the workflow physically cannot proceed until violations are resolved. There's no "ignore this warning" escape hatch.
How does the two-file extension convention work?
Each extension has an opt-in.md file (lightweight, always loaded — asks the user a yes/no question) and a full rules file (heavy, loaded only if the user opts in). This keeps the system prompt lean while allowing arbitrarily complex rule sets. Extensions without an opt-in file are always enforced — no user choice.
Can different team members use different IDEs on the same AI-DLC project?
Yes — this is explicitly supported. The workflow state in aidlc-docs/ is platform-agnostic. Developer A uses Cursor, Developer B uses Claude Code, Developer C uses Amazon Q. They all read and write the same aidlc-docs/aidlc-state.md and artifact files. The only IDE-specific files are the rule file locations, and those contain identical content.
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
AI Coding Agent Architecture: Agent Loop Deep Dive
Explore how Claude Code, Cursor, Aider, and Cline work under the hood. Agent loops, tool dispatch, and edit strategies explained.
AI Engineering, Agent FrameworksHow to Build Claude Code Skills: 5 Examples (2026)
Build custom Claude Code Skills with 5 ready-to-use examples. Covers SKILL.md spec, security controls, plugin distribution, and team sharing workflows.
AI Development Tools, Developer Productivity, Claude CodeOpenClaw vs Hermes: Context Compression Cuts Cost 75%
See how two top AI agents cut token costs ~75% using prompt caching, frozen memory, and 5-phase context compression — with real source code.
AI Engineering, Agent Frameworks