Intelligent Document Processing: OCR & AI Classification
How a production IDP pipeline turns 500-page medical-legal bundles into structured data with OCR and a 3-level LLM classification hierarchy.
Intelligent Document Processing: OCR & AI Classification (Part 1)
TL;DR: Intelligent Document Processing (IDP) is the discipline of turning unstructured document bundles into structured, queryable data. This two-part series distills the architecture patterns behind a production IDP pipeline that ingests large medical and legal bundles. Part 1 covers the perception half: upload and storage, OCR, and a three-level classification hierarchy that tags every page using overlapping batches and priority-based merging. Part 2 covers the action half — routing, data extraction, and timeline generation. The lessons are framed as reusable patterns, not a specific codebase.
Key Takeaways
- An IDP pipeline is not one model call. It is a staged system — upload → OCR → classify → route → annotate → timeline — where classification quality gates everything downstream.
- OCR and AI classification should be decoupled. OCR completion does not need to trigger classification; a downstream pipeline pulls the stored OCR output when ready, which gives the system a natural backpressure point and prevents a burst of uploads from stampeding the LLM tier.
- Classification is most robust when it is hierarchical: a coarse document type, a primary per-page type, and a fine-grained per-page sub-type. The document-level label is best derived from the page labels, not predicted directly.
- Long documents should be split into overlapping batches (a small overlap of a couple of pages). Overlap means boundary pages get classified more than once; conflicts resolve by a priority order where more specific categories win.
- Model selection is a deliberate cost/accuracy trade: a cheap general LLM handles bulk page typing, while a fine-tuned or specialized model is reserved for the one sub-decision where accuracy pays for itself.
- Document-level labels should be derived with fuzzy thresholds on category counts, not simple presence, so that one stray page does not relabel an entire bundle.

What Problem Does Intelligent Document Processing Actually Solve?
Imagine a clerk opening a new case and uploading what an institution sent over: a single 480-page PDF. Inside that one file are clinical notes, months of progress notes, an itemized bill with adjustment columns, an explanation-of-benefits statement, a lien letter, two fax cover sheets, and an ID card someone scanned sideways. None of it is labeled. The page order is whatever the scanner produced.
The job of an IDP pipeline is to read that bundle the way an experienced clerk would: figure out what each page is, throw away the noise, pull the facts that matter (dates, amounts, names, providers), and assemble them into something a human can act on. The difference is that the clerk handles one bundle an afternoon, and the pipeline handles thousands a day.
I want to be precise about the word "processing" here, because it hides a lot. When people say "we use AI to process documents," they usually mean one model call against one page. A production pipeline is a different animal. The system I have in mind runs documents through six distinct stages, and the interesting engineering is almost never in the model. It is in the orchestration around the model: where state lives, how you chunk a document that does not fit in a context window, how you reconcile contradictory classifications, and what you do when OCR returns garbage on page 3 of 480.
The mental model I keep coming back to is perception, then action. The first three stages perceive the document: get the pixels into text, then decide what every page is. The last three act on that perception, routing the document, extracting structured facts, and building a timeline. This article is Part 1: perception. Part 2 is action.
How Is the Pipeline Structured End to End?
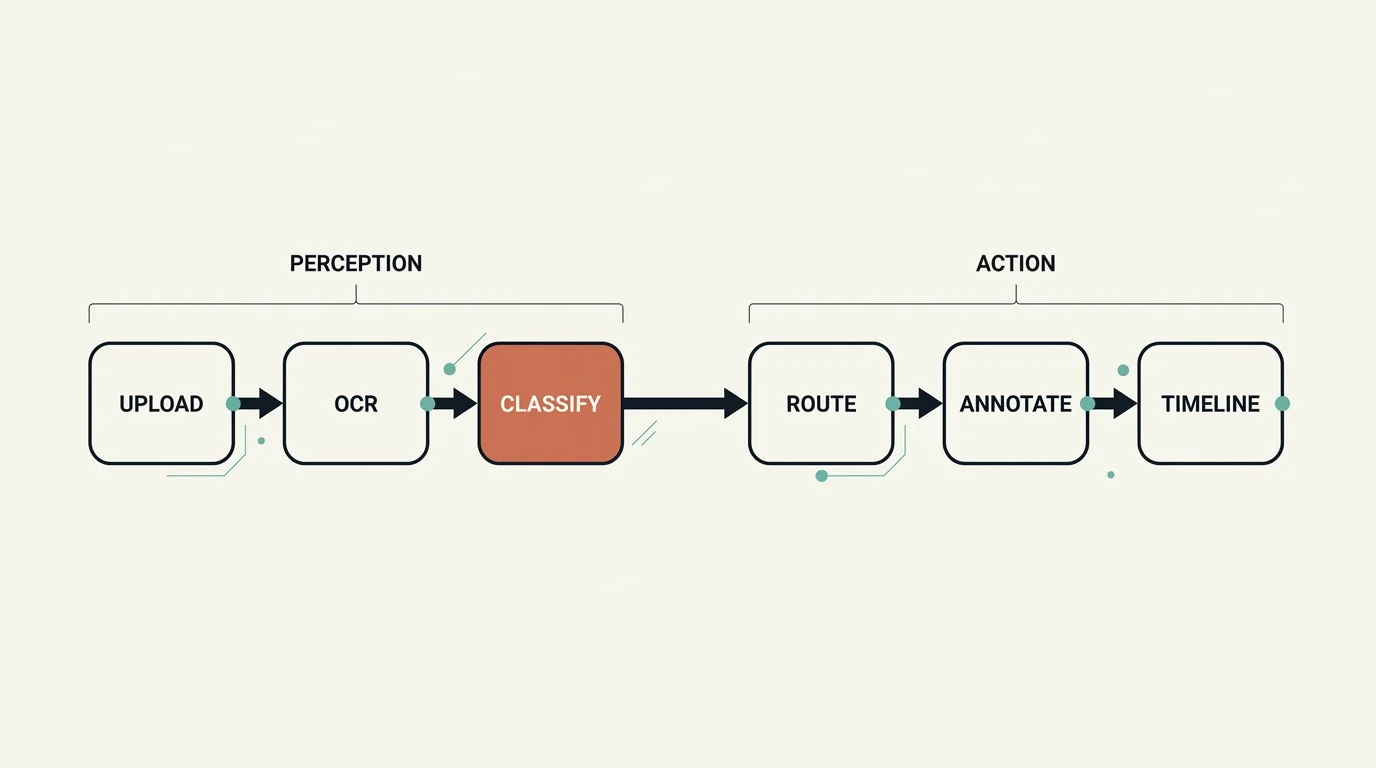
At the highest level, a document moves through these stages:
- Upload & Storage — the document lands in object storage and a job record is created.
- OCR — an OCR service extracts text, tables, and key-value pairs; output is stored as structured JSON.
- Classify — an LLM tags each page with a type and sub-type, plus quality and source.
- Route — a decision step skips low-value documents and forwards the rest.
- Annotate — structured data (line items, events) is extracted from the kept documents.
- Timeline — events from all documents in a case are merged into a chronological view.
One detail trips up almost everyone the first time they meet this kind of architecture: classification is not a separate stage that fires the moment OCR finishes. Classification belongs inside the downstream pipeline as its first step. The reason is mundane but important — classification needs the OCR text to exist, and OCR is asynchronous and can take minutes. So you decouple them. OCR writes its output to storage and stops. The document sits in a pending state. Later, a queue processor (or a manual request, or a batch regeneration) triggers the pipeline, which reads the stored OCR output and runs classification as step one.
That decoupling is the first real architecture decision worth internalizing. If OCR directly triggered classification, a burst of uploads would create a thundering herd of LLM calls the moment OCR finished, and you would have no natural place to apply backpressure. By landing everything in a pending state and pulling work through a queue, the system controls its own throughput.
A useful pattern at this layer is to give each store one job:
That per-document metadata blob is worth flagging now because it recurs in Part 2. It accumulates state as the document moves through the pipeline: classification status, the page-level outline, the derived document types, routing flags. Treat it as the document's working memory.
How Does OCR Work, and Why Two Output Formats?
OCR is the unglamorous foundation. If the text extraction is wrong, every downstream model inherits the error, and no amount of prompting recovers a date the OCR never read. So the pipeline takes it seriously and runs OCR as a managed, asynchronous service behind a serverless function.
There are usually two ways a document reaches OCR, and they exist for different operational reasons. The first is a direct storage trigger: an object-created event on the upload bucket fires a function that kicks off OCR and registers a notification channel for completion. This is the standard path for ordinary uploads. The second is a workflow-orchestrated path: when OCR is one step inside a larger orchestrated workflow, a state machine invokes the OCR step carrying a callback token, and signals the workflow to advance only when OCR completes. The token is the whole point — it lets a long, async OCR step participate in a synchronous-looking workflow without polling.
Here is the part I found non-obvious: it pays to store the OCR result in two formats, and they are not redundant.
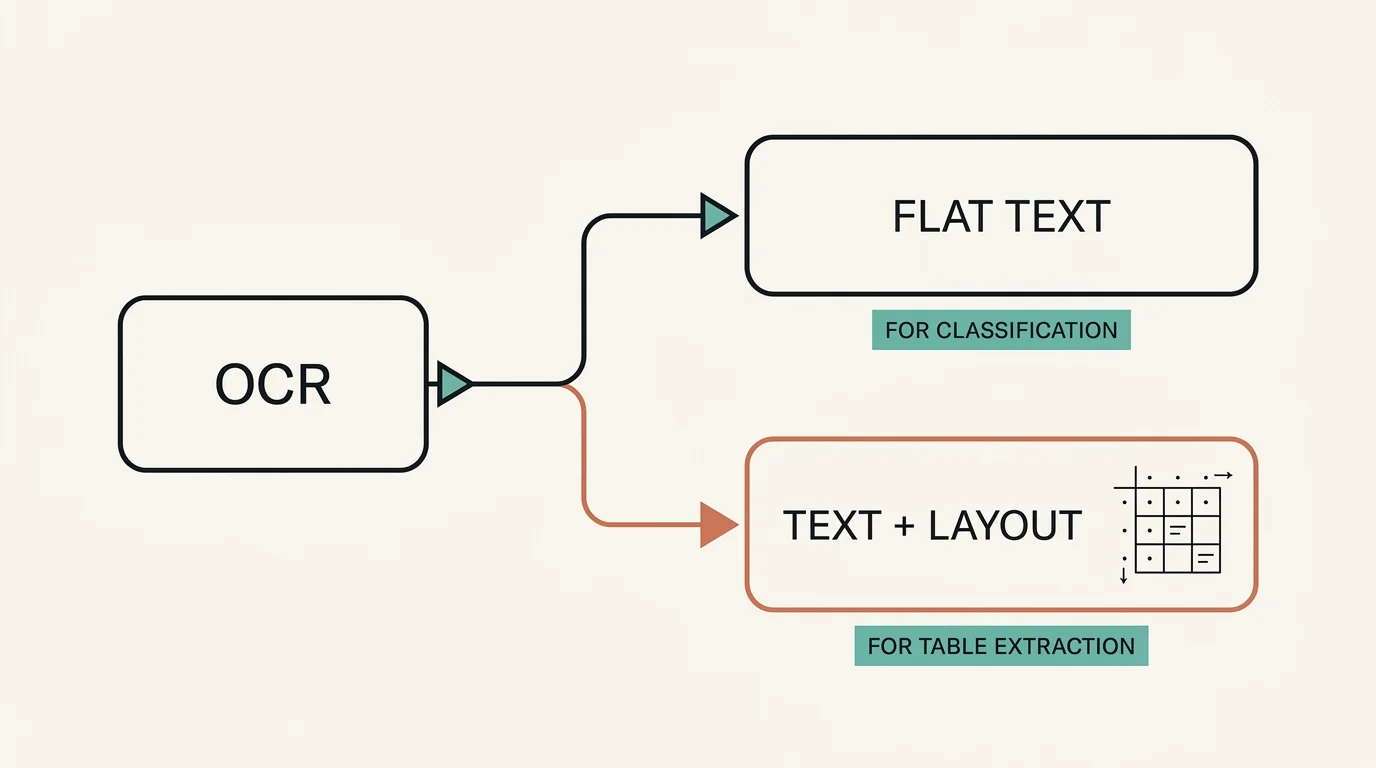
The flat-text format is just a list of page text — one string per page. That is all classification needs: the LLM reads text, decides a type, and never cares where on the page a word sat. Keeping a lightweight representation means the classifier loads less data and runs faster.
The layout-preserving format keeps everything: block types, bounding boxes, table structure, confidence scores. Table extraction needs this. To parse an itemized bill correctly you have to know which numbers sit in the same row and which column they fall under — geometry is the data. Throwing away bounding boxes would force the parser to guess at table structure from a flattened text stream, exactly the kind of brittle heuristic you want to avoid.
So the rule is: store the cheap format for the cheap consumers, store the expensive format for the one consumer that needs it. Two representations of the same OCR pass, each shaped for its reader.
How Does the Three-Level Classification Hierarchy Work?
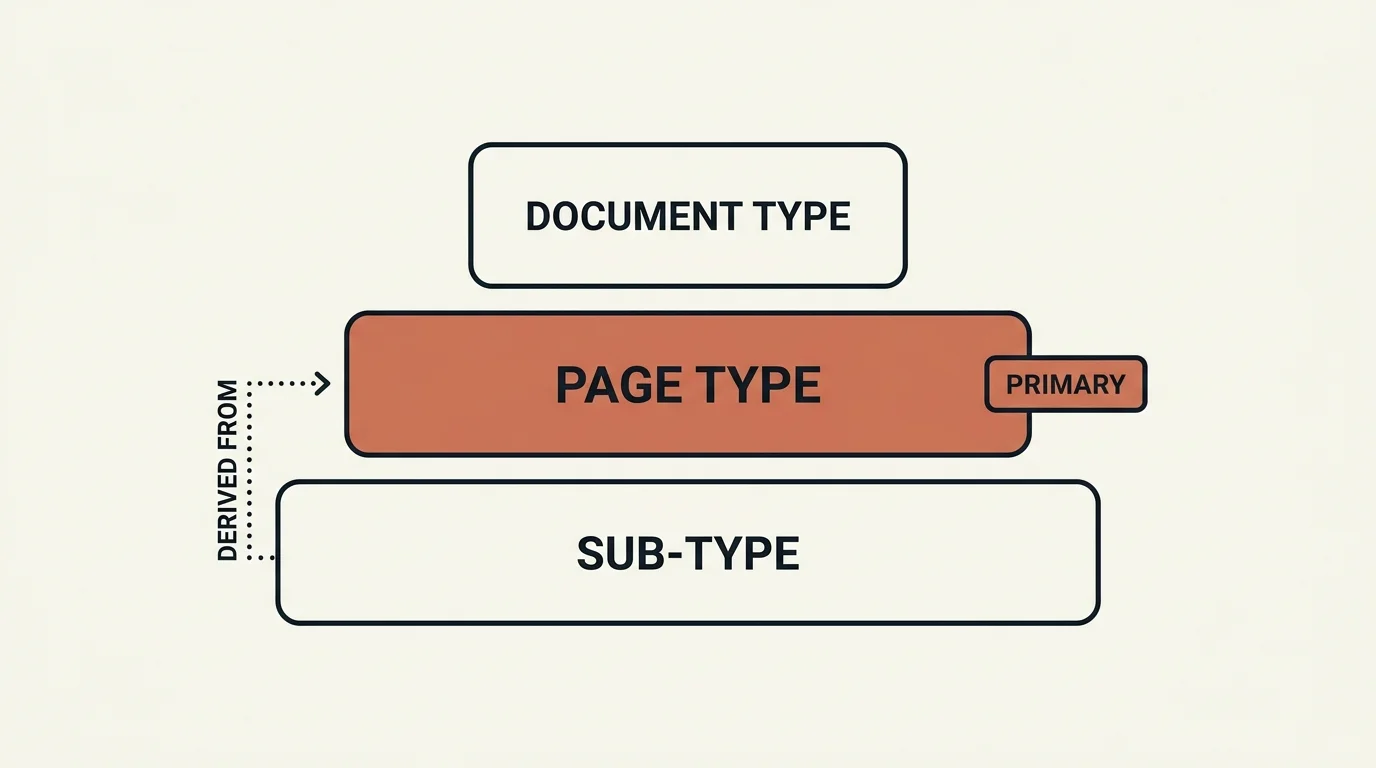
Classification works best at three levels of granularity, and the relationship between them is the thing to get right.
Level 1: Page type — the primary signal
Every page is assigned exactly one category from a small, fixed set — in a legal/medical setting that might be clinical, financial, non-medical financial, incident report, legal, and administrative/other. This is the foundational classification; everything else derives from it. A general-purpose LLM reads each page's text and assigns the category, plus a quality score, a source/provider name, and a handwriting flag. The per-page output is a small record carrying the type, an optional sub-type, the provider, the page number, and quality.
Level 2: Page sub-type — fine-grained, per parent
Once a page has a top-level type, a second pass assigns a sub-type specific to that type. Financial pages get billing-specific sub-types (standard bills, bills with adjustment/payment columns, various lien types, explanation-of-benefits, pharmacy charges, and so on). Clinical pages get relevance-oriented sub-types (critical, important, ignorable). Incident pages separate official reports from facility/property reports. Legal pages key off discovery-specific signals (depositions, complaints, interrogatories, production requests, disclosures).
The interesting design choice is mixing model types by sub-decision. Most sub-types ride on a cheap general LLM with a good prompt, because the categories key off textually obvious signals — literal phrases the model can match. But the one high-stakes, judgment-heavy sub-decision — clinical relevance — is better served by a fine-tuned or specialized model, because "is this page clinically critical?" is a judgment call rather than a keyword match, it runs on a huge share of pages, and getting it wrong is expensive in both directions (burning tokens annotating worthless letterhead, or worse, ignoring a page that documents a critical procedure).
A robust hierarchy also needs an answer for the degenerate cases: page types that have no sub-types get an explicit "no sub-classification" sentinel, and a classification failure gets an explicit error value rather than a silent gap. The goal is that every page ends up with a well-typed result, even the empty and error cases — no undefined leaking downstream.
Level 3: Document type — derived, never classified
Here is the inversion that surprised me. You might expect the system to ask an LLM "what type of document is this?" It should not. Document-level labels are best computed from the page-level outline.
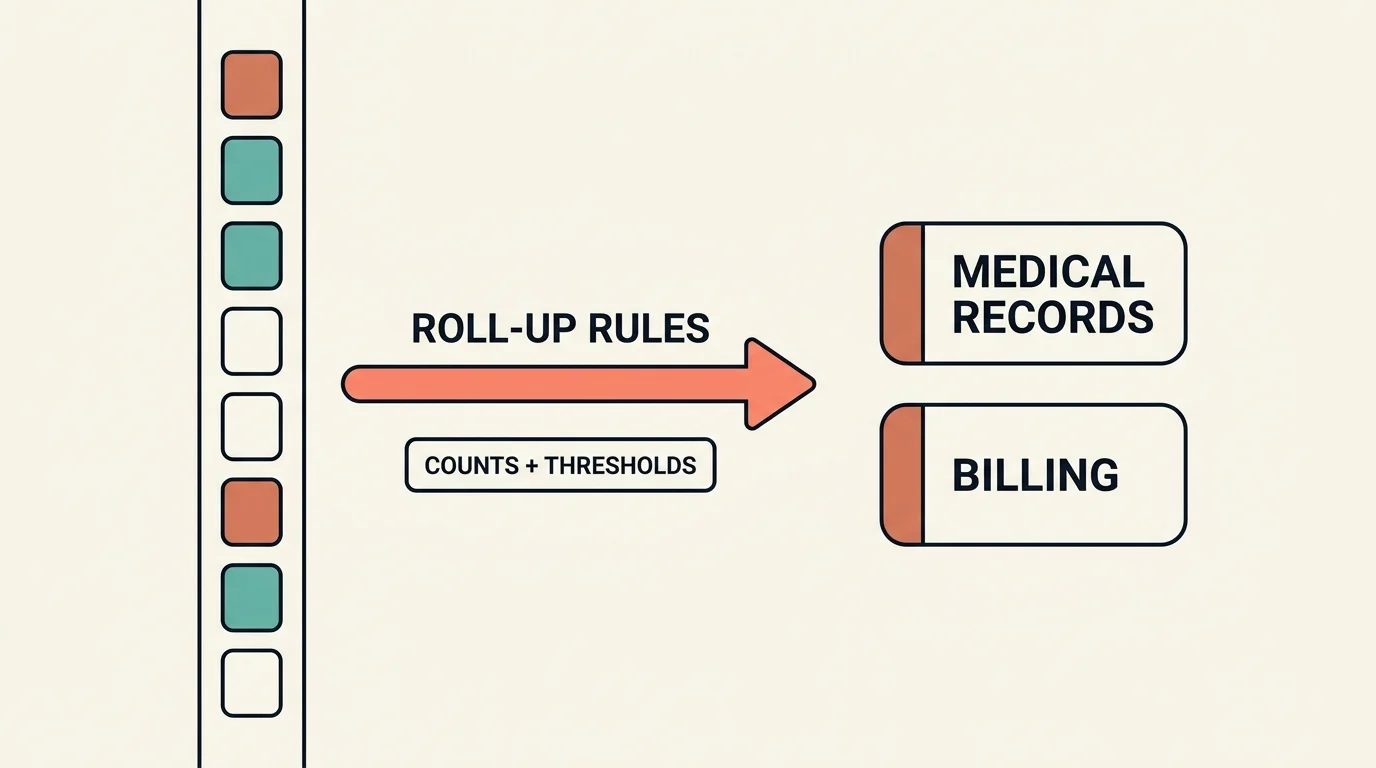
A document can carry multiple labels simultaneously (a bundle that is both medical records and billing). The derivation uses different rules per label, and the asymmetry is the point. Some labels can be assigned on simple presence — if any financial page exists, the document is "billing." But the medical-records label uses a fuzzy threshold on sub-type counts, not presence, because clinical pages are noisy. A 400-page billing bundle might have one page of clinical notes stapled in by accident, and simple presence would mislabel the whole thing as medical records and route it into expensive clinical annotation.
So medical-record detection counts the clinical sub-types and checks proportions: roughly, a document qualifies if its share of critical pages clears a low single-digit-percent bar, OR its share of important pages clears a slightly higher bar, OR its share of even-low-value clinical pages clears a larger bar. The counts are cumulative — the "important" bucket includes critical pages, the "ignore" bucket includes the rest — with a small slack constant so a handful of stray pages doesn't trip the threshold. The exact numbers are tuned per corpus and matter less than the shape: even a tiny fraction of high-value pages should flag the document, while it takes a large fraction of low-value pages to do the same. The thresholds encode a judgment about which mistakes are expensive.
How Do You Classify a 500-Page Document That Won't Fit in Context?
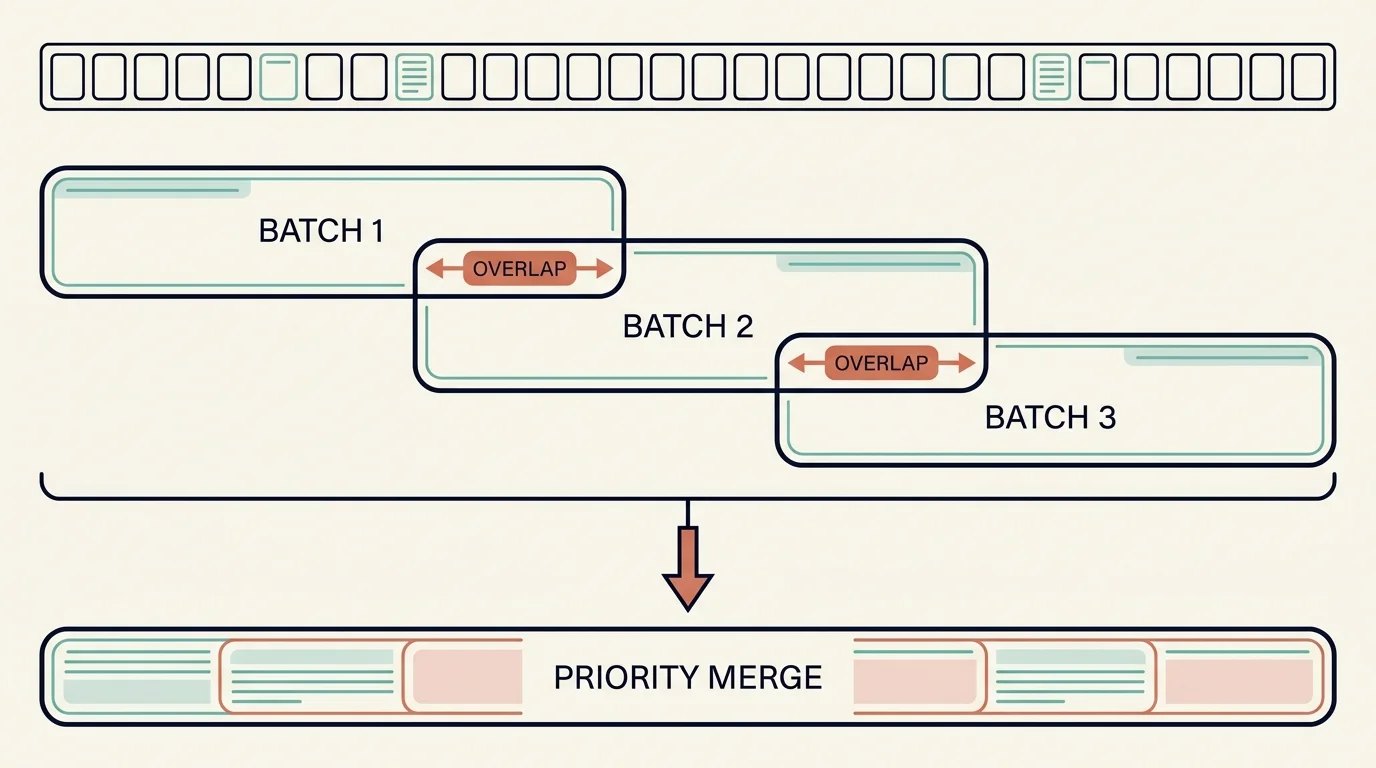
You cannot paste 500 pages into a single LLM call: it overflows the model's token limit, and even within the window, a page rarely classifies correctly without the surrounding pages for context. The pipeline solves this with a layered chunking strategy of overlapping batches and priority-based merging.
Overlapping batches
Pages are split into batches of roughly 15 with a small overlap of a couple of pages, giving an effective stride a little shorter than the batch size. The overlap exists because a page in isolation is often ambiguous. A record spanning a batch boundary should not be cut with no shared context, and a source name that appears only in a section header needs to carry forward. Overlap buys context across the seam.
A small practical trick lives inside each batch: when you concatenate pages into one prompt, label them with a numeric marker that starts from a high, unusual base (something well clear of any number that would appear in the document body). If you numbered batch pages 1–15 and the document text said "see page 5," the model can cross the wires between its batch index and a page reference printed in the content. Starting the markers at an out-of-range base removes that ambiguity. It is the kind of detail you only add after a model confidently mislabels a page because it read an internal cross-reference.
Batches run concurrently. If the model returns the wrong number of classifications for a batch, the system retries those pages individually and, failing that, marks them with an explicit error type — so the invariant exactly one classification per page always holds.
Priority-based merge
Overlap means some pages get classified twice. When one batch says a page is "clinical" and the adjacent batch says "other," you need a deterministic tie-breaker. Resolve conflicts by a priority order where more specific, higher-value categories outrank generic ones: clinical beats other, a specific bill type beats "miscellaneous financial," critical beats important. The reasoning is that a confident specific classification carries more signal than a vague one, and in this domain the cost of under-classifying (treating a high-value page as "other" and skipping it) is higher than over-classifying.
Contiguous runs for sub-classification
Sub-classification should only run on pages of the matching parent type, and those pages should be grouped into contiguous runs so unrelated sections never get analyzed together.
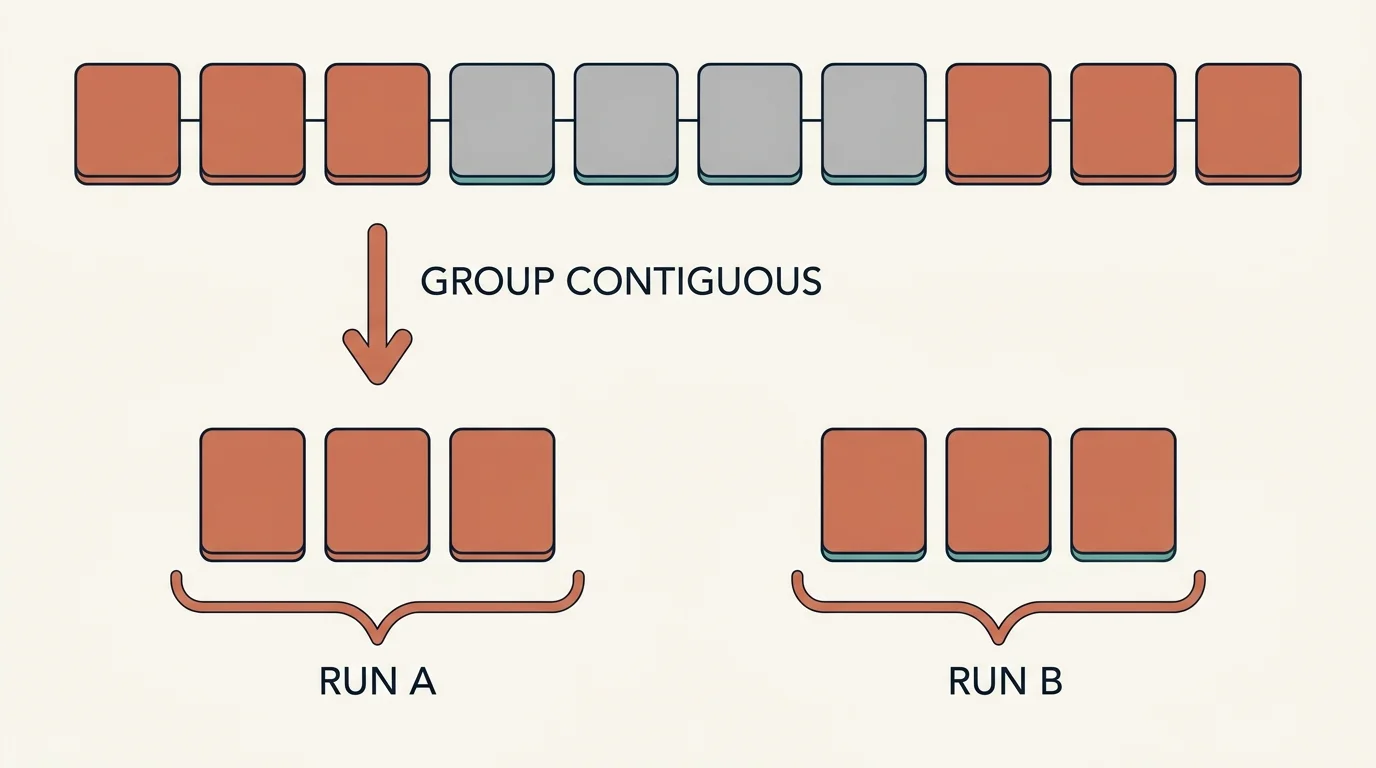
If a document has bills on pages 1–20 and again on 81–100 with clinical records in between, you do not want to classify those two billing sections as one blob — they are different sources, different dates, different structure. Grouping the filtered pages into contiguous runs keeps each section's context intact while still skipping the unrelated material in the middle.
Context enhancement
Two cheap pieces of context the model would otherwise miss lift accuracy. First, filename context: a file named for its source or type is a strong hint, so prepend the filename to the page text during sub-classification. Second, source backfilling — records often print the provider/source in a section header on the first page only, so continuation pages should inherit the last-known source rather than coming back blank.
Where the work runs in parallel
Parallelize aggressively, but with a ceiling. Quality assessment and page-type classification can run concurrently; all batches run concurrently; all contiguous runs run concurrently. The one guardrail that matters is a bounded concurrency limit on how many documents generate outlines at once, so a flood of uploads cannot exhaust memory or saturate database connections. A small fixed cap is enough.
One historical note worth keeping, because it is a good lesson in not over-optimizing: a system like this often grows a sampling layer that processes only a fraction of pages for low-priority cases to save cost. It is easy for that to become dead code once business requirements shift to full processing for every case. The lesson is that selective sampling is a real optimization, but it is also the kind of conditional path that quietly stops running — worth auditing what your code actually executes versus what it merely contains.
What Does the Finished Page Outline Contain?
The end product of all this is a page outline: a per-page array of small records, each carrying the page's type, sub-type, source, and quality. A representative slice reads like "page 1: clinical, critical, Memorial Hospital, high quality; page 85: financial, standard bill, Memorial Hospital, medium; page 150: clinical, ignorable, City Clinic, low."
Alongside it sits the set of derived document-level types, and a status flag flips to "classified." That outline is the contract between perception and action. Everything in Part 2 (the routing decision, which extractor runs, what ends up on the timeline) reads from this structure. Get the outline right and the rest of the pipeline has a fighting chance; get it wrong and no downstream cleverness saves you.
FAQ
What is the difference between IDP and plain OCR?
OCR converts pixels to text — it tells you what words are on a page. Intelligent Document Processing is the full pipeline that sits on top: it classifies what each page is, decides which documents matter, extracts structured fields, and assembles the results into something queryable. OCR is one stage (the second) inside IDP. A system that stops at OCR hands you a text dump; an IDP system hands you structured data with types, sources, dates, and relationships.
Why classify at the page level instead of the document level?
Real-world bundles are mixed. A single uploaded PDF routinely contains records, bills, filings, and administrative junk interleaved in arbitrary order. Document-level classification forces one label onto a heterogeneous file and loses the structure. Page-level classification captures the reality, where one page is a clinical note, another is a bill, and another is letterhead, and then derives document-level types from the page distribution. The page is the honest unit of classification.
Why use a specialized model for one sub-decision but prompts for the rest?
Cost versus accuracy. The high-stakes, judgment-heavy sub-decision (here, clinical relevance) is subtle, hard to express reliably in a prompt, and runs on a huge share of pages, so accuracy compounds — a fine-tuned model earns its training cost there. The other sub-types key off textually obvious signals (literal terms a prompt can match), where a cheap general model is plenty. Matching model investment to where it pays off is the pattern.
How does overlapping-batch classification avoid double-counting a page?
Overlap deliberately classifies boundary pages more than once, then reconciles. After all batches return, a merge step walks every page and, where two batches disagree, keeps the higher-priority (more specific) category using a fixed priority order. The invariant maintained throughout is exactly one final classification per page, so the duplication helps accuracy at the seams without inflating the page count.
Does OCR completion trigger classification automatically?
It should not, and assuming it does is a common misreading of this kind of architecture. OCR writes its output to storage and marks its job complete, but it does not kick off the downstream pipeline. The document waits in a pending state until a queue processor, a manual request, or a batch regeneration pulls it forward. Decoupling OCR from classification gives the system a natural backpressure point and prevents a burst of uploads from stampeding the LLM tier.
This is Part 1 of a two-part series on building a production Intelligent Document Processing pipeline. Part 2 covers routing, data extraction, and timeline generation →
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
IDP Part 2: Routing, Extraction & Timeline Generation
The action half of a production IDP pipeline: skip-routing, structured extraction, day-by-day timeline assembly, plus the queues and retries that scale it.
AI Engineering, Document AI, LLM ApplicationsContext Engineering for AI Agents: Cut LLM Costs 10x in 2026
Context engineering cuts AI agent costs 10x via KV cache optimization, tool masking, and 5 more patterns. Production-tested by teams running million-token workflows.
AI Engineering, Agent FrameworksAI Coding Agent Architecture: Agent Loop Deep Dive
Explore how Claude Code, Cursor, Aider, and Cline work under the hood. Agent loops, tool dispatch, and edit strategies explained.
AI Engineering, Agent Frameworks