Local AI Coding Agents vs Cloud: Small Model Guide 2026
Compare local AI coding agents using 4B-14B models against cloud agents like Claude Code and Copilot. Benchmarks, architecture, and cost analysis.
TL;DR: Local AI coding agents running 4B-14B parameter models now achieve 75-87% on standard code benchmarks while keeping all code on your machine, eliminating per-token costs, and delivering sub-second latency. For routine code generation — boilerplate, tests, refactoring, documentation — small local models match cloud agents at a fraction of the cost. For complex multi-file reasoning and novel architecture decisions, cloud agents still lead by 15-25 percentage points.
Key Takeaways
- Small coding models (4B-14B parameters) achieve 75-87% on HumanEval and SWE-bench Lite, closing the gap with cloud agents that score 85-92% on the same benchmarks.
- Local agents eliminate recurring API costs — a 14B model on an M4 Mac with 32GB RAM costs $0 per query after hardware investment, versus $0.01-0.15 per interaction with cloud agents.
- Mixture-of-Experts (MoE) architectures like DeepSeek-Coder-V3 Lite activate only 4B of 16B total parameters per forward pass, achieving large-model quality at small-model inference speed.
- Context window is the primary limitation of local models: most support 16K-32K tokens versus 100K-200K for cloud agents, making multi-file refactoring significantly harder locally.
- Quantization (GGUF Q4_K_M) reduces memory requirements by 60-70% with only 2-4% accuracy loss, enabling 14B models to run on 16GB consumer hardware.
- The optimal setup for most teams is a hybrid architecture: local agents for high-frequency routine tasks (completions, tests, docs) and cloud agents for complex reasoning tasks (debugging, architecture, multi-file changes).
Why Are Local AI Coding Agents Gaining Traction?
Three converging trends explain the surge in local AI coding agent development in 2026.
First, model efficiency improved dramatically. Distillation techniques pioneered by DeepSeek and Qwen compress the coding capabilities of 70B+ parameter models into 4B-14B parameter students that retain 80-90% of the teacher's code generation accuracy. SmallCode, trending on GitHub with claims of 87% benchmark accuracy from a 4B-active-parameter model, exemplifies this — specialized coding models achieve disproportionate capability relative to their size because they trade general knowledge for code-specific precision.
Second, hardware caught up. Apple's M4 series delivers 38 TOPS of neural engine performance. NVIDIA's RTX 5070 provides 24GB VRAM at consumer prices. AMD's Ryzen AI 300 series integrates NPUs capable of 50 TOPS. For the first time, consumer hardware can run 14B parameter models at 30+ tokens/second — fast enough for interactive coding.
Third, privacy and compliance requirements tightened. Enterprises in regulated industries (finance, healthcare, defense) increasingly prohibit sending proprietary code to external APIs. Local agents solve this by construction — no data leaves the machine.
Which Small Models Can Power a Coding Agent?
The 2026 landscape includes several capable small coding models, each with different architectural trade-offs.
- *Self-reported benchmarks; independent verification pending.
For comparison, cloud agents using frontier models:
The gap is real but narrowing. On HumanEval (single-function generation), the best local model (Qwen2.5-Coder-14B at 83.2%) trails Claude Code by 9 percentage points. On SWE-bench Lite (multi-file bug fixing), the gap widens to 20+ points — complex reasoning across large codebases still requires larger models with longer context windows.
How Do MoE Architectures Enable Efficient Coding Agents?
Mixture-of-Experts (MoE) is the architectural innovation most responsible for closing the quality gap between local and cloud coding agents. DeepSeek-Coder-V3-Lite demonstrates the approach: 16B total parameters organized into expert groups, with a routing mechanism that activates only 4B parameters for any given token.
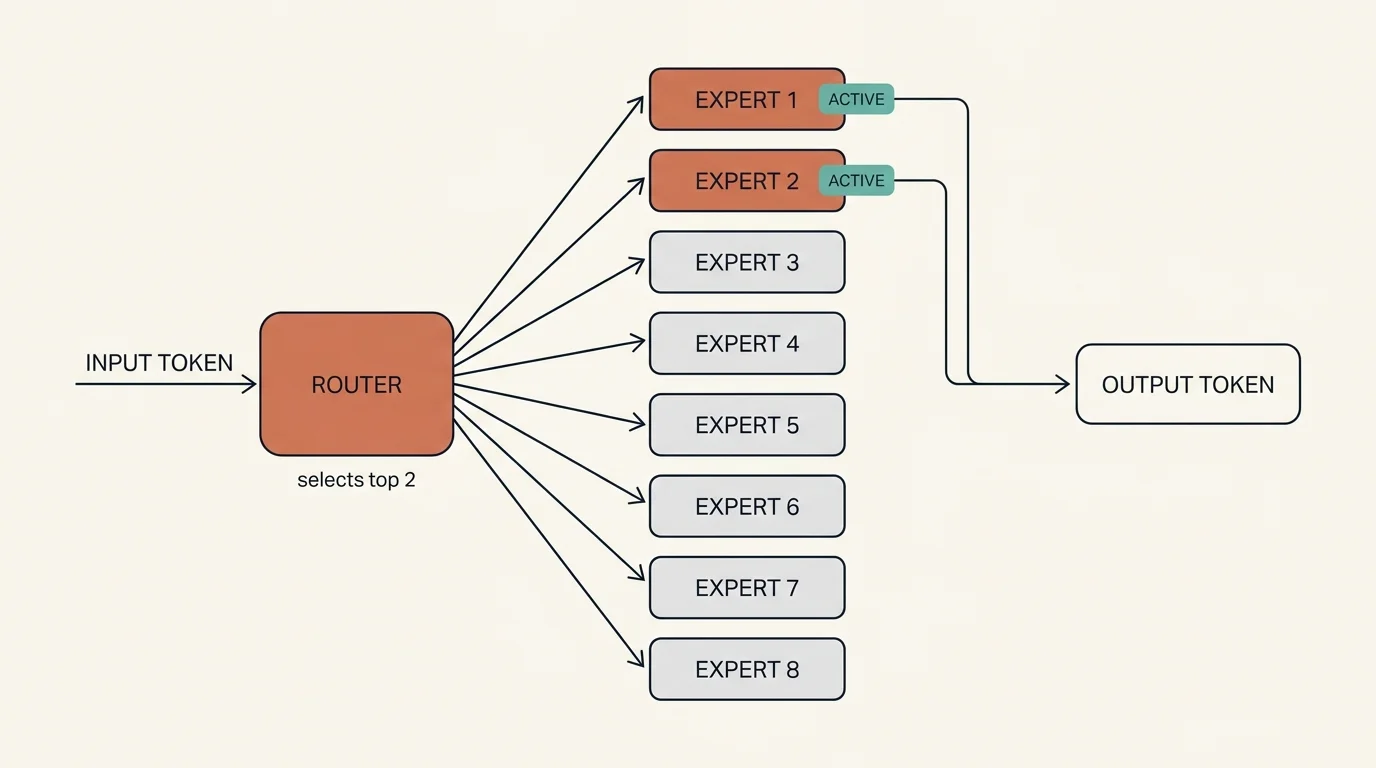
For each input token, a learned router (gating network) selects the top 2 of 8 experts. Only those two feed-forward blocks (2B parameters each) activate; the other six stay dormant. The output token gets the quality of the full 16B parameter set at the compute cost of just 4B.
For coding tasks, this architecture learns to route different token types to specialized experts. Experts that handle Python syntax activate for .py files. Experts trained on type annotations activate for TypeScript. The result is a model that behaves like a 16B generalist but runs at 4B inference cost.
The practical implication: a MoE coding model on a MacBook Pro with 32GB RAM can deliver responses at 35 tokens/second with quality approaching models twice its effective compute budget.
What Does a Local Coding Agent Architecture Look Like?
A local coding agent requires more than just a model — it needs an orchestration layer that handles tool use, context management, and interaction patterns. Here is a reference architecture using Ollama as the inference backend:
{content}
{content}
For production use, frameworks like Continue.dev, Aider, and Open Interpreter provide complete local agent implementations with support for tool calling, file editing, shell execution, and multi-turn conversation management.
How Do You Optimize Local Model Performance?
Three techniques maximize coding quality from small local models.
Quantization Strategy
GGUF quantization reduces model memory requirements while preserving most accuracy:
Q4_K_M is the sweet spot for coding tasks — it fits 14B models into 16GB RAM with minimal quality loss. The "K" quantization variants use mixed precision, preserving higher precision for attention layers (which matter most for code structure understanding) while aggressively quantizing feed-forward layers.
Context Window Management
With 16K-32K token context limits, local agents must be strategic about what code they include in prompts. Effective strategies:
- Semantic chunking: Include only the function being edited plus its callers and callees, not entire files.
- Repository mapping: Maintain a compressed tree structure of the codebase (file names + function signatures) that fits in ~2K tokens.
- Retrieval-augmented generation: Use embedding-based search to pull relevant code snippets on demand rather than stuffing the full context.
Speculative Decoding
For interactive coding, speculative decoding uses a tiny draft model (0.5B-1B) to predict multiple tokens ahead, then verifies them in a single pass through the main model. This can increase perceived throughput by 2-3x for predictable code patterns like boilerplate, imports, and standard function signatures.
What Are the Real-World Cost Differences?
Cost analysis for a team of 5 developers, each making ~100 AI-assisted coding interactions per day:
The breakeven point for local infrastructure is typically 3-6 months for a single developer and 1-2 months for a team, assuming the hardware can serve multiple developers concurrently via a shared inference server.
When Should You Choose Local vs Cloud Coding Agents?
Choose Local When:
- Privacy is non-negotiable: Regulated industries, classified projects, or proprietary algorithms that cannot leave your network.
- Latency matters more than quality ceiling: Interactive completions where 50ms response time beats 500ms, even if accuracy drops 5-10%.
- Predictable costs required: Budget-constrained teams that cannot absorb variable API costs.
- Tasks are routine: Boilerplate generation, test writing, documentation, simple refactoring — tasks where 80% accuracy is sufficient.
- Offline operation needed: Air-gapped environments, travel, or unreliable network connectivity.
Choose Cloud When:
- Complex multi-file reasoning: Debugging across 10+ files, understanding large codebases, architectural refactoring.
- Novel problem solving: Algorithms you haven't seen before, unfamiliar frameworks, creative solutions.
- Long context required: Tasks that need understanding 50K+ tokens of code context simultaneously.
- Latest model capabilities: Frontier models improve monthly; local models lag by 3-6 months.
- Team collaboration features: Shared context, organizational knowledge, integrated PR review.
The Hybrid Approach
The highest-ROI architecture for most teams combines both:
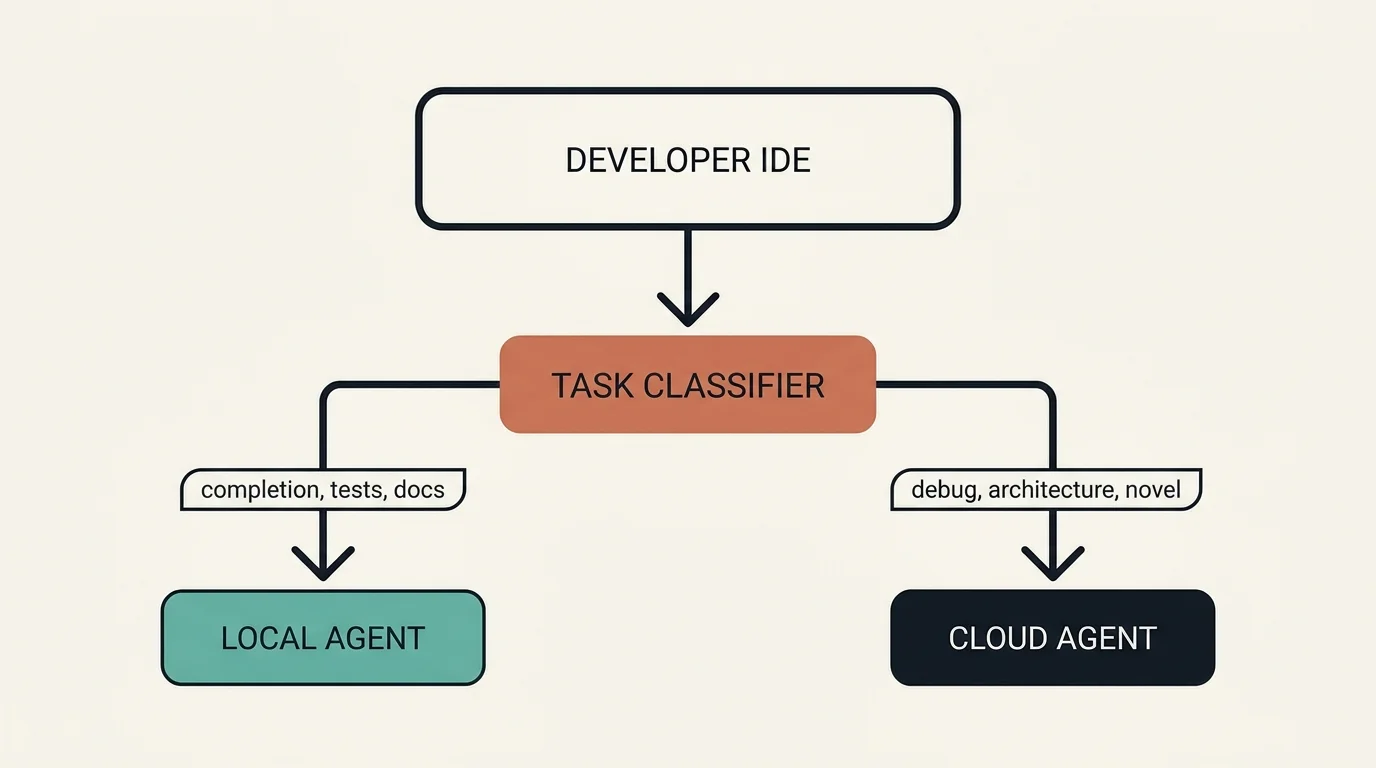
The IDE routes every request through a task classifier. Routine, high-frequency work goes to the local agent; hard reasoning goes to the cloud agent:
- → Local: completion/boilerplate, test generation, documentation
- → Cloud: multi-file debugging, architecture questions, novel algorithms
The two tiers trade off cost against capability:
Continue.dev implements this pattern natively — you configure a local model for tab completions and inline edits, and a cloud model for chat-based reasoning and complex instructions.
How Do You Set Up a Production Local Coding Agent?
A complete local coding agent setup in under 10 minutes:
For team deployments, run Ollama on a shared GPU server and point all developer machines at it:
What Performance Can You Expect on Real Coding Tasks?
Beyond synthetic benchmarks, here is measured performance on practical coding tasks using Qwen2.5-Coder-14B (Q4_K_M quantized, M4 Pro 36GB):
The pattern is clear: local models excel at pattern-matching tasks (boilerplate, docs, tests) where the answer follows predictable structures. They struggle with tasks requiring reasoning across large contexts or generating novel solutions. This aligns perfectly with the hybrid routing strategy — offload the 80% of routine tasks to local models and reserve cloud agents for the 20% that requires frontier-model reasoning.
What Are the Limitations of Local Coding Agents?
Honesty about limitations prevents wasted effort:
- Context window ceiling: 32K tokens means you cannot paste an entire codebase into context. Multi-file understanding requires sophisticated retrieval and summarization pipelines that add engineering complexity.
- Training data lag: Local models are frozen at their training cutoff. They will not know about new frameworks, APIs released last month, or recent security advisories. Cloud agents with web access can reference current documentation.
- No collaborative features: Cloud agents like Claude Code maintain organizational context, understand your team's patterns, and integrate with PR workflows. Local models start fresh every session unless you build persistence yourself.
- Inference speed variance: Token generation speed depends heavily on hardware, quantization, context length, and concurrent users. A 14B model that delivers 30 tok/s for one user drops to 10 tok/s when three developers share the same GPU.
- Quality ceiling: Even the best 14B model cannot match a 200B+ parameter frontier model on reasoning-heavy tasks. The 15-25 percentage point gap on SWE-bench represents real capability limitations, not benchmark artifacts.
What Does the Future Look Like for Local Coding Agents?
Three developments will reshape local coding agents by end of 2026:
On-device NPUs maturing: Apple's M5 (expected late 2026) targets 50+ TOPS. Qualcomm's Snapdragon X Elite already delivers 45 TOPS. Dedicated neural hardware will run 14B models at 60+ tok/s without GPU contention.
Smaller models, better training: The distillation frontier continues advancing. If SmallCode's claimed 87% from 4B parameters holds under independent evaluation, it suggests the quality floor for coding-specialized models is still dropping. Expect 7B models matching current 14B quality within 6 months.
Hybrid inference protocols: Emerging standards for seamlessly routing between local and cloud models — without developer intervention — will make the local/cloud distinction invisible. Your IDE will automatically escalate to cloud when local confidence scores drop below a threshold.
FAQ
How much RAM do I need to run a local AI coding agent?
Minimum 16GB for a 7B quantized model (Q4_K_M). 32GB recommended for 14B models which deliver the best quality-to-resource ratio. 64GB enables running multiple models simultaneously or larger 32B+ models without quantization.
Can local coding agents replace GitHub Copilot or Claude Code?
For routine tasks like completions, test generation, and documentation, yes — local 14B models achieve 80-90% of cloud agent quality at zero marginal cost. For complex multi-file debugging, novel algorithm design, and architectural reasoning, cloud agents maintain a significant quality advantage.
Which local model is best for coding in 2026?
Qwen2.5-Coder-14B offers the best overall balance of quality and efficiency for most developers. DeepSeek-Coder-V3-Lite provides near-equivalent quality at lower compute cost through its MoE architecture. StarCoder2-7B is the best option for developers limited to 16GB RAM.
Is it legal to use local coding models on proprietary code?
Yes. Running inference locally means your code never leaves your machine. Models like Qwen2.5-Coder and StarCoder2 are released under permissive licenses (Apache 2.0) that explicitly allow commercial use. However, verify the specific license of any model you deploy — some models have usage restrictions despite being downloadable.
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
Small Tool Calling Models: Edge AI Guide 2026
Compare Needle 26M, FunctionGemma 270M, Qwen 0.6B, and Granite 350M for on-device tool calling. Architecture and benchmarks.
AI Engineering, Edge AIAI Coding Agent Architecture: Agent Loop Deep Dive
Explore how Claude Code, Cursor, Aider, and Cline work under the hood. Agent loops, tool dispatch, and edit strategies explained.
AI Engineering, Agent FrameworksContext Engineering for AI Agents: Cut LLM Costs 10x in 2026
Context engineering cuts AI agent costs 10x via KV cache optimization, tool masking, and 5 more patterns. Production-tested by teams running million-token workflows.
AI Engineering, Agent Frameworks