6 Best AI Agent Frameworks 2026: LangChain vs AgentCore vs CrewAI
Agent frameworks 2026 compared: LangChain leads ecosystem with 95K stars, AgentCore offers managed AWS runtime, LangGraph excels at complex workflows. Production benchmarks included.

AI Agent Frameworks: The Complete Guide for 2026
TL;DR: AI agent frameworks provide the runtime loop, tool integration, and memory management needed to build autonomous LLM-powered systems. In 2026, six frameworks dominate: LangChain, AgentCore, LangGraph, CrewAI, AutoGen, and Strands -- each optimized for different architectural trade-offs between control, scalability, and operational complexity.
Key Takeaways
- LangChain remains the most widely adopted general-purpose framework with 95K+ GitHub stars and the largest ecosystem of integrations, but its abstraction layers add latency and debugging complexity at scale.
- Amazon Bedrock AgentCore is the only fully managed runtime for production agents, eliminating infrastructure management with auto-scaling, IAM-native security, and built-in memory -- at the cost of AWS lock-in.
- LangGraph treats agents as directed state graphs with explicit checkpointing, making it the strongest choice for workflows requiring human-in-the-loop, branching logic, or reproducible replay.
- CrewAI and AutoGen solve the multi-agent coordination problem differently: CrewAI uses role-based delegation with sequential/parallel execution modes; AutoGen uses conversational message-passing between specialized agents.
- Strands Agents SDK (open-sourced by AWS in 2025) provides a model-driven approach with minimal abstraction -- the LLM controls the entire agent loop, resulting in simpler code but less deterministic execution.
- No single framework wins across all dimensions. Production teams increasingly compose multiple frameworks: LangGraph for orchestration logic, AgentCore for deployment, and Strands for lightweight tool-calling agents.
What are AI agent frameworks?
An AI agent framework is a software library or platform that provides the core primitives for building autonomous systems powered by large language models. These primitives include the agent loop (observe-think-act cycle), tool integration interfaces, memory and state management, and orchestration patterns for multi-step or multi-agent workflows.
The distinction between a framework and a raw LLM API call is autonomy. When you call Claude or GPT-4 directly, you get a single response. An agent framework wraps that call in a loop: the model observes its environment (tool outputs, user messages, memory), decides on an action, executes it, and repeats until the task is complete or a termination condition is met. The framework handles the plumbing -- serializing tool calls, managing conversation state, enforcing guardrails, routing between models, and recovering from errors.
By 2026, the landscape consolidated from dozens of experimental libraries to six production-viable options, each reflecting a different opinion about how much control the developer versus the model should have over execution flow.
How do AI agent frameworks work?
Every agent framework implements a variation of the same fundamental loop:
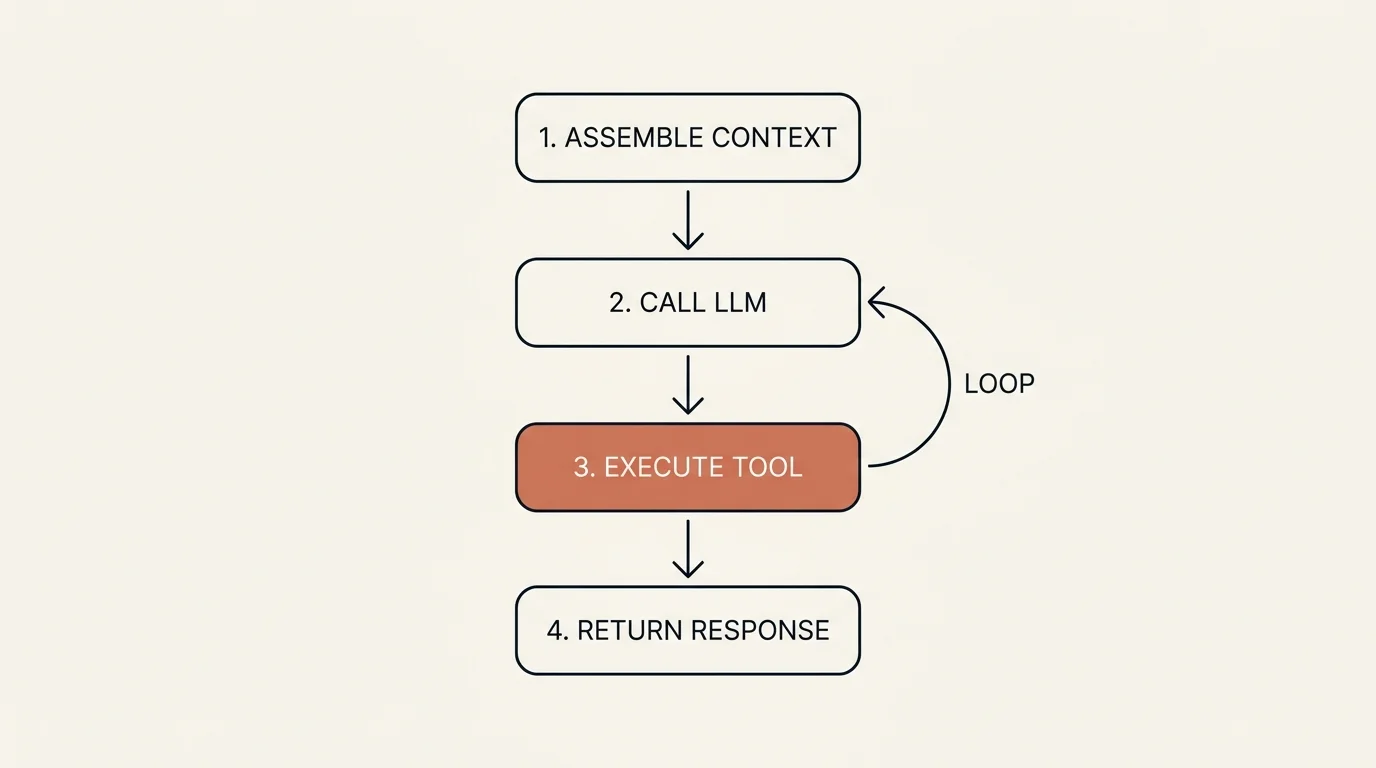
- Assemble context — system prompt + memory + tool definitions + conversation history + observations from the last step.
- Call the LLM with that context. The model returns either plain text or a tool call.
- If it's a tool call: validate and execute the tool, append the result to the context, and go back to step 2.
- If it's text (no tool call): return the final response to the user, or trigger the next agent in the chain.
The frameworks diverge in four architectural dimensions:
State management. LangGraph uses explicitly typed state objects with checkpointing at every node. AgentCore provides managed memory with semantic search across sessions. CrewAI maintains shared context between crew members. Strands lets the model manage its own context with minimal framework interference.
Tool integration. All frameworks support function-calling via model-native tool_use APIs. The differences are in discovery (static registration vs. MCP dynamic discovery), execution sandboxing (AgentCore provides isolated containers; LangChain executes in-process), and error handling (Strands surfaces raw errors to the model; LangGraph can route to recovery nodes).
Orchestration topology. Linear chains (LangChain), directed graphs with cycles (LangGraph), hierarchical delegation (CrewAI), peer-to-peer message passing (AutoGen), and flat model-driven loops (Strands) represent fundamentally different approaches to multi-step execution.
Memory architecture. Short-term (conversation buffer), working memory (current task state), and long-term (persistent across sessions) are handled differently by each framework. AgentCore provides all three as managed services. LangChain requires you to compose memory backends. LangGraph checkpoints state but does not provide cross-session persistence natively.
Which AI agent framework should you choose in 2026?
The decision matrix below compares the six major frameworks across dimensions that matter for production systems:
The short version: If you need maximum flexibility and ecosystem breadth, start with LangChain. If you need managed production infrastructure on AWS, use AgentCore. If your workflow has complex branching, cycles, or human approval steps, use LangGraph. If you need multiple specialized agents collaborating, choose CrewAI (simpler) or AutoGen (more powerful). If you want minimal abstraction and trust the model to drive execution, use Strands.
What is LangChain and when should you use it?
LangChain (v0.3+, 2026) is the most widely adopted LLM application framework, providing composable abstractions for chains, agents, retrievers, and memory. Its core philosophy is flexibility through composition: every component is swappable, every integration is optional, and the framework imposes minimal opinions on architecture.
Strengths: The ecosystem is unmatched -- 750+ integrations covering vector stores, document loaders, LLM providers, tools, and output parsers. LangChain Expression Language (LCEL) enables declarative pipeline construction with streaming, batching, and fallbacks built in. The community produces tutorials, templates, and third-party extensions at a pace no competitor matches.
Weaknesses: Abstraction overhead is real. LangChain's layered architecture (core → community → integrations → application) means simple tasks require understanding multiple abstraction levels. Debugging agent failures requires tracing through callback chains. Performance-sensitive applications often find that removing LangChain and calling model APIs directly reduces latency by 30-50ms per step. The framework's rapid evolution (breaking changes between minor versions through 2024-2025) has stabilized but left documentation debt.
Use when: You are building RAG pipelines, need to prototype agent architectures quickly, require model-agnostic abstractions, or want access to the broadest ecosystem of pre-built integrations. Avoid when execution predictability and minimal latency are critical.
What is Amazon Bedrock AgentCore?
AgentCore (GA 2025) is Amazon's fully managed platform for deploying and operating production AI agents. It provides five managed services: Runtime (auto-scaling agent hosting with session isolation), Memory (persistent semantic memory with cross-session search), Code Interpreter (sandboxed execution environments), Browser (cloud-based web automation), and Gateway (MCP-based tool integration with authentication).
Strengths: Operational simplicity is the primary value proposition. AgentCore handles scaling, security (IAM-native), monitoring (CloudWatch integration), credential rotation, and infrastructure provisioning. Memory service provides semantic search across agent sessions without managing vector databases. The Runtime accepts agents built with any framework (LangChain, LangGraph, Strands, or raw code) -- it is not an agent logic framework but a deployment platform.
Weaknesses: AWS lock-in is significant. Your agents depend on IAM, CloudWatch, Bedrock model access, and AgentCore-specific APIs. Multi-cloud or on-premise deployment is not possible. Pricing is opaque (pay-per-use on five separate services plus underlying Bedrock model costs). Cold starts on Runtime can add 2-5 seconds on first invocation. The service is relatively new with limited community content compared to open-source alternatives.
Use when: Your organization is committed to AWS, you need production-grade infrastructure without building it, security/compliance requirements demand managed IAM integration, or you want to separate agent logic development from deployment operations.
What is LangGraph and how does it differ?
LangGraph (v0.4+, maintained by LangChain Inc.) models agents as directed graphs where nodes are computation steps and edges define transitions based on state. Unlike LangChain's linear chains or simple ReAct agents, LangGraph supports cycles, conditional branching, parallel execution, and human-in-the-loop interrupts -- all with built-in state checkpointing.
Strengths: Explicit state management eliminates the ambiguity of implicit conversation context. Every node reads from and writes to a typed state object. Checkpointing enables pause/resume, time-travel debugging, and replay -- critical for production agents handling sensitive workflows. Human-in-the-loop patterns (approval gates, corrections, escalations) are first-class primitives, not afterthoughts. The graph structure makes complex workflows visualizable and testable.
Weaknesses: The graph abstraction adds conceptual overhead for simple use cases. A basic tool-calling agent that takes 15 lines with Strands requires 50+ lines in LangGraph. Debugging requires understanding state transitions, channel updates, and checkpoint serialization. LangGraph Cloud (managed hosting) is a separate paid product; self-hosting requires managing persistence backends for checkpoints.
Use when: Your agent workflow has conditional logic, approval gates, error recovery branches, parallel tool execution with merge points, or any pattern that looks more like a workflow engine than a simple loop. LangGraph is the right choice when you need reproducibility and auditability.
What are CrewAI and AutoGen for multi-agent systems?
CrewAI and AutoGen both solve the multi-agent coordination problem -- multiple specialized AI agents collaborating on a task -- but with fundamentally different metaphors.
CrewAI (v0.80+, 2026) uses a crew/role metaphor. You define agents with specific roles (Researcher, Writer, Critic), assign them tasks, and specify a process (sequential, hierarchical, or parallel). A manager agent can delegate dynamically. CrewAI is opinionated and concise: defining a multi-agent workflow takes 30-50 lines of Python. It integrates with LangChain tools and supports custom LLM providers.
AutoGen (v0.4+, Microsoft) uses conversational message-passing. Agents communicate by sending messages to each other in group chats, with configurable termination conditions and speaker selection policies. AutoGen supports nested conversations, code execution, and complex debate patterns. It is more powerful than CrewAI for research-style tasks where agents need to challenge and refine each other's outputs.
CrewAI strengths: Simplicity, fast setup, intuitive role-based mental model, good for content generation and research pipelines. Weaknesses: Limited control over inter-agent communication, less suited for adversarial or debate-style workflows.
AutoGen strengths: Flexible conversation topologies, strong for code generation with execution feedback, Microsoft ecosystem integration, active research community. Weaknesses: Higher complexity, more boilerplate, conversation management can be unpredictable, .NET support is ahead of Python in some features.
Choose CrewAI for straightforward delegation workflows (research → write → review). Choose AutoGen for complex multi-turn agent debates, code generation with iterative testing, or when you need fine-grained control over agent communication patterns.
How do you build a production AI agent?
Production agents differ from prototypes in five critical dimensions: reliability (graceful degradation), observability (tracing every decision), cost control (token budgets), security (tool sandboxing), and scalability (concurrent sessions). Here is a reference architecture using framework-agnostic patterns:
Key production patterns demonstrated:
- Iteration caps prevent infinite loops (common in ReAct agents that get stuck retrying failed tools).
- Token budgets prevent runaway costs from verbose tool outputs or recursive planning.
- Error isolation returns errors to the model as tool results rather than crashing the loop -- models are remarkably good at recovering from tool failures when they can see the error message.
- Output truncation prevents context window overflow from large tool returns (database queries, file reads).
- State externalization enables checkpointing, replay, and multi-session continuity.
For production deployment, add: structured logging, OpenTelemetry tracing, per-user rate limiting, tool-level permission scoping, and circuit breakers on external dependencies.
What are the common mistakes with agent frameworks?
After building and reviewing dozens of production agent systems, these are the failure modes I see repeatedly:
1. Over-engineering the framework choice. Teams spend weeks evaluating frameworks for a problem that requires 50 lines of direct API calls. If your agent calls 2-3 tools in a linear sequence, you do not need LangGraph's state machine or CrewAI's multi-agent coordination. Start with the simplest possible loop and add framework complexity only when the problem demands it.
2. Ignoring context window economics. Every tool result, every conversation turn, every system prompt token costs money on input and degrades model performance as the window fills. Production agents that run for 30+ steps without context compression will hit quality cliffs where the model starts ignoring earlier instructions. Implement aggressive summarization, tool output truncation, and sliding window strategies.
3. Treating tool failures as system failures. When a tool raises an exception, the worst thing you can do is crash the agent loop. Return the error to the model as a tool result. Models with tool-use training will attempt alternative approaches, ask clarifying questions, or gracefully report that the task cannot be completed. The model's error recovery is often better than your hand-coded retry logic.
4. No observability from day one. Agent failures are notoriously difficult to reproduce. The model chose a different path, the tool returned different data, the context was slightly different. Without structured traces of every decision point, debugging is guesswork. Integrate tracing before you deploy, not after the first production incident.
5. Confusing orchestration with intelligence. Adding more agents, more tools, and more complex graph topologies does not make your system smarter. A single well-prompted agent with three focused tools will outperform a five-agent crew with thirty tools in most practical scenarios. Complexity is a cost, not a feature. Multi-agent architectures are justified only when tasks require genuinely different capabilities or perspectives.
6. Hardcoding model selection. Frameworks make it easy to bind a specific model (e.g., gpt-4o or claude-sonnet-4-20250514) throughout your agent. Production systems should abstract model selection behind configuration, enabling you to swap models for cost optimization, fallback on outages, or upgrade without code changes. The performance gap between frontier models is narrowing -- your framework choice should outlast any single model generation.
FAQ
What is the best AI agent framework for beginners?
Strands Agents SDK offers the lowest barrier to entry. Its model-driven philosophy means you write a system prompt, define tools as Python functions with docstrings, and the framework handles the rest. A functional agent takes under 20 lines of code. LangChain is the next step up -- more abstraction to learn, but vastly more tutorials and community support. Avoid LangGraph and AutoGen until you understand the basic agent loop, as their additional complexity (state graphs, multi-agent messaging) obscures fundamentals.
How do AI agent frameworks handle memory?
Three tiers exist across frameworks. Short-term memory is the conversation buffer within a single session (all frameworks provide this). Working memory is task-specific state that persists across tool calls within a workflow -- LangGraph's typed state objects and CrewAI's shared context serve this role. Long-term memory persists across sessions and requires external storage -- AgentCore provides this as a managed service with semantic search; LangChain requires you to integrate a vector store (Pinecone, Chroma, Weaviate) manually; Strands defers to the developer entirely. The choice depends on whether your agents need to remember past interactions: customer support agents need long-term memory; one-shot code generation agents do not.
Can you combine multiple agent frameworks?
Yes, and production teams increasingly do. The most common pattern is using LangGraph or CrewAI for orchestration logic and deploying the resulting agent on AgentCore Runtime for managed scaling. Another pattern: use Strands for lightweight tool-calling sub-agents that are orchestrated by a LangGraph parent graph. LangChain tools and retrievers can be used inside LangGraph nodes or CrewAI agents without conflict. The key constraint is state management -- if you mix frameworks, you need a clear contract about which framework owns the conversation state and checkpoint lifecycle.
What's the difference between agents and chains?
A chain is a fixed sequence of operations: input → transform → LLM call → output parser → result. The execution path is determined at design time. An agent is a dynamic loop: the LLM decides which action to take at each step based on observations, and the execution path is determined at runtime. Chains are predictable, fast, and easy to test. Agents are flexible, slower, and harder to debug. Use chains when the workflow is known in advance (RAG pipelines, structured extraction). Use agents when the workflow depends on runtime conditions (tool selection based on user input, iterative refinement based on intermediate results). LangGraph blurs this boundary by allowing you to define graphs that include both deterministic edges (chain-like) and conditional edges (agent-like) in the same workflow.
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
AgentCore vs LangChain: 2026 Framework Guide
Compare AgentCore and LangChain for AI agents. Architecture, pricing, and deployment trade-offs explained with code.
AI Engineering, Agent FrameworksAgentCore vs LangGraph: Agent Orchestration Compared (2026)
Compare AgentCore and LangGraph for AI agent orchestration. State management, deployment, and pricing explained with code.
AI Engineering, Agent FrameworksContext Engineering for AI Agents: 6 Techniques That Cut Our Costs 10x
One misplaced timestamp invalidated our entire KV cache and 10x'd our bill. Here are 6 context engineering patterns from Manus and production agent teams that prevent exactly this -- with code examples.
AI Engineering, Agent Frameworks