Multimodal Models Learning Notes - A Beginner's Guide
Learn multimodal AI from scratch. Embedding, understanding, and generation paradigms with CLIP, Qwen2.5-VL, and Sora examples.
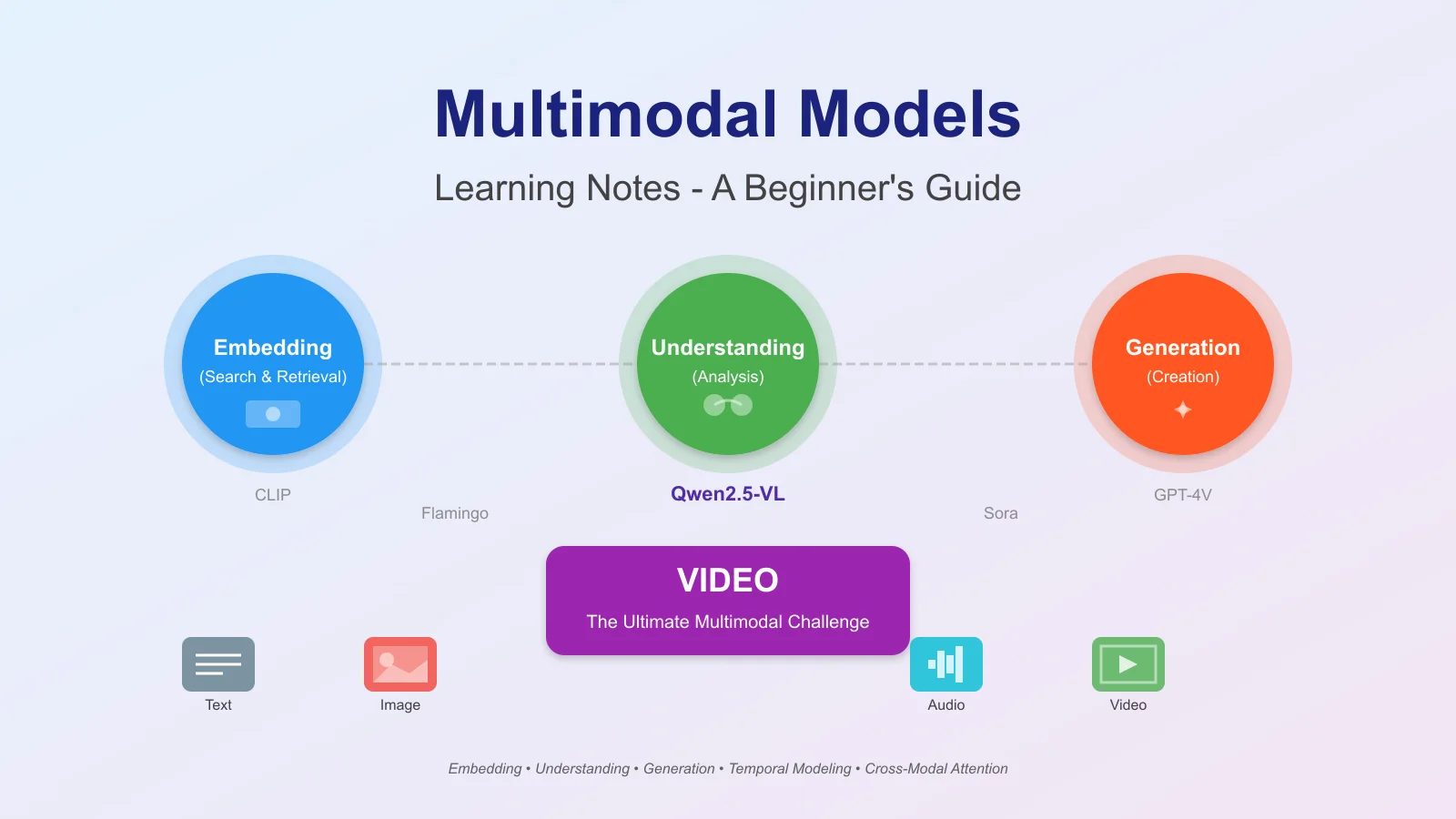
TL;DR: Multimodal AI models process text, images, audio, and video through three paradigms: embedding, understanding, and generation. This beginner guide covers architectures from CLIP to Qwen2.5-VL with practical code examples for video processing.
Multimodal Models: A Beginner's Learning Journey
What are multimodal AI models, and how do they process text, images, audio, and video simultaneously? This beginner-friendly guide covers the three pillars of multimodal AI -- embedding (search and retrieval), understanding (analysis and comprehension), and generation (creation and synthesis) -- with detailed architecture comparisons, code examples, and practical implementation insights from CLIP to Qwen2.5-VL.
Key Takeaways
- Multimodal models process multiple data types (text, images, audio, video) simultaneously, and the core challenge is aligning representations across modalities with fundamentally different statistical properties.
- Three paradigms define multimodal AI: embedding (mapping modalities to shared spaces for search), understanding (extracting meaning from combined inputs), and generation (creating content across modalities).
- CLIP and contrastive learning form the foundation for multimodal embeddings, enabling cross-modal search like finding images with text queries or retrieving video moments by description.
- Qwen2.5-VL (2025) represents the state of the art, introducing dynamic-resolution ViT, absolute time encoding for hour-long videos, and window attention for computational efficiency.
- Video is the ultimate multimodal challenge, combining spatial, temporal, audio, and textual signals -- requiring hierarchical processing, efficient attention mechanisms, and multi-scale feature fusion.
- Production systems need adaptive frame sampling, mixed-precision inference, and hierarchical aggregation to handle real-world video processing at scale.
Historical Context and Evolution
The journey of multimodal AI began with simple fusion techniques in the 1990s, evolving through several key phases:
- Early Fusion Era (1990s-2000s): Simple concatenation of features
- Deep Learning Revolution (2010s): CNN+RNN architectures for vision-language tasks
- Transformer Era (2017+): Attention mechanisms enabling better cross-modal understanding
- Foundation Model Era (2020+): Large-scale pre-training on massive multimodal datasets
What Are Multimodal Models?
Multimodal models are AI systems that can process, understand, and generate content across multiple data types (modalities) such as text, images, audio, and video. Think of them as AI systems that can "see," "hear," and "speak" simultaneously.
The Fundamental Challenge: Representation Alignment
The core challenge in multimodal learning is the heterogeneity gap - different modalities have fundamentally different statistical properties:
The Three Pillars of Multimodal AI
1. Multimodal Embedding (Search & Retrieval)
Core Concept: Creating unified representations where different modalities can be compared in the same space.
Mathematical Foundation:
The goal is to learn projection functions f_text and f_image such that:
- Similar concepts have high cosine similarity: cos(f_text("dog"), f_image(dog_image)) ≈ 1
- Dissimilar concepts have low similarity: cos(f_text("cat"), f_image(car_image)) ≈ 0
Key Characteristics:
- Maps different data types to a shared embedding space
- Enables cross-modal search (e.g., search images with text)
- Uses contrastive learning to align representations
Contrastive Learning Process:
Advanced Architectures Beyond CLIP:
Video-Specific Embedding Challenges:
- Temporal Modeling: Videos have temporal dynamics that static embeddings miss
- Computational Cost: Processing all frames is expensive
- Semantic Granularity: Matching can happen at frame, shot, or video level
Advanced Video Embedding Techniques:
Real-world Applications:
2. Multimodal Understanding (Analysis & Comprehension)
Core Concept: Extracting meaning and relationships from multiple modalities simultaneously.
Theoretical Foundation - Information Theory Perspective:
- Complementarity: I(X;Y|Z) > 0 - Each modality provides unique information
- Redundancy: I(X;Y) > 0 - Modalities share common information
- Synergy: I(X,Y;Z) > I(X;Z) + I(Y;Z) - Combined modalities reveal more than sum of parts
Video Understanding Tasks Hierarchy:
Advanced Architecture Patterns:
Video-Language Understanding Deep Dive:
- Temporal Grounding: Localizing moments in video from natural language
- Hierarchical Video Understanding:
- Frame Level: Object detection, pose estimation
- Shot Level: Action recognition, scene understanding
- Scene Level: Narrative comprehension, emotional arc
- Video Level: Genre classification, summarization
State-of-the-Art Video Understanding Models:
Case Study: Qwen2.5-VL - A Modern Multimodal Understanding Architecture
Qwen2.5-VL represents the cutting edge of multimodal understanding models (2025), showcasing several architectural innovations that address longstanding challenges in video understanding:
1. Dynamic Resolution Vision Transformer:
2. Key Technical Innovations:
3. Multi-Scale Processing Capabilities:
4. Performance Characteristics:
5. Unique Capabilities for Video Understanding:
- Second-level Event Localization: Can pinpoint exact moments in hour-long videos
- Interactive Visual Agent: Can reason about visual input and execute real-world tasks
- Document Understanding: Excels at charts, diagrams, and structured layouts
- Multi-turn Reasoning: Maintains context across extended conversations about visual content
Advanced Video Feature Extraction:
3. Multimodal Generation (Creation & Synthesis)
Core Concept: Creating content in one modality based on input from another.
Mathematical Foundations:
- Conditional Generation: P(Y|X) where Y is generated modality, X is input modality
- Cross-Modal Translation: Learning mapping function f: X → Y
- Latent Space Alignment: Shared representation Z where X → Z → Y
Evolution of Video Generation Techniques:
Advanced Video Generation Architectures:
Text-to-Video Generation Pipeline:
Video Generation Challenges & Solutions:
State-of-the-Art Video Generation Models (2024-2025):
Multimodal Editing and Manipulation:
- Video Editing with Natural Language:
- "Remove the person in red shirt" → Inpainting
- "Make it sunset" → Style transfer
- "Add slow motion to the jump" → Temporal manipulation
- Cross-Modal Style Transfer:
- Audio → Video synchronization
- Text description → Visual style
- Reference image → Video aesthetics
- Interactive Generation Loop:
Deep Dive: Video Multimodal Systems
Video as the Ultimate Multimodal Challenge
Video represents the most complex multimodal data type, combining:
- Spatial information (2D frames)
- Temporal dynamics (motion, events)
- Audio signals (speech, music, effects)
- Textual elements (subtitles, OCR)
Advanced Video Processing Techniques
1. Efficient Video Encoding Strategies:
2. Temporal Reasoning Architectures:
Video-Specific Multimodal Challenges
1. Temporal Alignment Problem:
- Audio and visual events may not align perfectly
- Speech and lip movements synchronization
- Background music and scene transitions
2. Computational Scaling:
3. Memory and Attention Mechanisms:
Lessons from Qwen2.5-VL Implementation
The Qwen2.5-VL architecture provides several important lessons for building production multimodal systems:
1. Native Multimodal Design:
Instead of adapting pre-trained vision models, training a ViT from scratch for multimodal tasks yields better alignment between modalities.
2. Efficiency Through Window Attention:
3. Absolute Time Encoding for Long Videos:
4. Unified Architecture Benefits:
- Single model for multiple tasks (understanding, localization, generation)
- Shared representations improve cross-task performance
- Reduced deployment complexity
Technical Challenges & Solutions
Comprehensive Challenge Analysis
Architectural Evolution: From CLIP to Qwen2.5-VL
Practical Implementation Insights
Video Multimodal System Architecture
Implementation Decision Tree
When to Use Each Paradigm:
Production Considerations for Video Systems
1. Infrastructure Requirements:
2. Optimization Strategies:
Current State & Future Directions
2024-2025 Landscape:
- Unified Foundation Models:
- Single model for all modalities (GPT-4V, Gemini)
- Reduced deployment complexity
- Better cross-modal understanding
- Efficient Architectures:
- Mixture of Experts for modalities
- Dynamic computation based on input
- Edge-friendly models
- Real-world Applications:
- Autonomous vehicles (vision + lidar + maps)
- Medical diagnosis (scans + reports + audio)
- Content creation (text → video workflows)
Emerging Trends:
Key Takeaways for Beginners
- Video is Complex: Start with frame-based approaches before tackling temporal modeling
- Modality Alignment is Key: The hardest part is making different data types comparable
- Efficiency Matters: Video processing is expensive - always consider optimization
- Leverage Pretrained Models: Don't train from scratch unless absolutely necessary
- Think Hierarchically: Process video at multiple temporal scales
- Native Multimodal Design Wins: Models like Qwen2.5-VL show that training specifically for multimodal tasks outperforms adapted single-modal models
- Window Attention is Practical: For long videos, windowed attention provides a good balance between performance and computational cost
Advanced Example: Production Video Search System
Resources for Further Learning
Research Papers
- Foundations: "Attention Is All You Need" (2017) - Transformer architecture
- Video Understanding: "Video Understanding with Large Language Models" (2023)
- Multimodal Models: "Flamingo: a Visual Language Model for Few-Shot Learning" (2022)
- State-of-the-Art: "Qwen2.5-VL: Native Dynamic-Resolution Vision-Language Model" (2025) - arxiv:2502.13923
Open Source Projects
- OpenCLIP: Production-ready CLIP implementations
- VideoLLaMA: Video understanding with LLMs
- Weaviate: Vector database with multimodal support
Datasets
- Video: Kinetics-400, ActivityNet, HowTo100M
- Multimodal: WebVid-10M, LAION-5B, WIT
Commercial APIs
- OpenAI: GPT-4V for multimodal understanding
- Anthropic: Claude 3 with vision capabilities
- Google: Gemini Pro Vision
- AWS: Bedrock with multimodal models
The multimodal AI landscape is rapidly evolving, with video being the frontier challenge. Success requires understanding both theoretical foundations and practical engineering constraints. Start simple, iterate fast, and always measure performance across multiple dimensions.
Frequently Asked Questions
What are multimodal AI models?
Multimodal AI models are systems that process, understand, and generate content across multiple data types simultaneously -- including text, images, audio, and video -- by aligning representations from different modalities into shared embedding spaces.
How does CLIP compare to Qwen2.5-VL?
CLIP (2021) uses fixed-resolution dual encoders for image-text contrastive learning with limited video support. Qwen2.5-VL (2025) introduces dynamic-resolution ViT, absolute time encoding for hour-long videos, and window attention for computational efficiency across all modalities.
Who should learn about multimodal models?
Developers building video search systems, content moderation tools, accessibility features, or any application requiring AI to process combined visual, audio, and textual inputs will benefit from understanding multimodal model architectures.
What are the key benefits of multimodal AI?
- Enables cross-modal search like finding images with text queries or retrieving video moments by description
- Provides unified understanding of complex media combining spatial, temporal, and audio signals
- Supports generation tasks including text-to-video, image editing, and style transfer
- Reduces deployment complexity through single models handling multiple tasks simultaneously
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
Best AI Video Search Tools 2026: 10+ Tested
Which AI video search platform wins? TwelveLabs, Google Video AI, and 8 open-source tools tested on accuracy, speed, and cost.
Multimodal AI, Video SearchDeepSeek VL2 vs Janus in 2026: 4 Multimodal Models Compared
DeepSeek shipped 4 open-source multimodal models in 10 months. Compare VL2 MoE architecture vs Janus unified encoding. Benchmarks show which beats GPT-4V on vision tasks.
Multimodal AI, DeepSeek