How to Add Long-Term Memory to LangChain AI Agents in 2026
Add long-term memory to LangChain AI agents: 3 frameworks compared (LangChain, AgentCore, Strands). See code examples, scaling from 10K to 1M+ users, and persistence options.

AI Agent Memory Management: LangChain vs AgentCore vs Strands Compared
TL;DR: AI agent memory management differs significantly across LangChain, Bedrock AgentCore, and Strands Agents. LangChain offers maximum flexibility with multiple memory types. Bedrock provides fully managed AWS-native memory with compliance features. Strands uses a minimalist model-driven approach. Choosing the right framework depends on scale (< 10K users = Strands, 10K-1M = LangChain+LangMem, 1M+ = Bedrock), compliance needs, and desired control over memory lifecycle.
Key Takeaways
- LangChain offers the most flexible and extensible memory system with multiple memory types (buffer, summary, entity) and broad storage backend support, making it ideal for customizable agent workflows.
- Amazon Bedrock AgentCore provides a fully managed, enterprise-grade memory service with built-in session and long-term memory, best suited for AWS-integrated production deployments.
- Strands Agents takes a minimalist, model-driven approach to memory with straightforward session storage, prioritizing simplicity and rapid prototyping.
- Context engineering -- strategically managing what information reaches the LLM's context window -- is critical for agent performance across all three frameworks.
- Each framework implements a distinct memory hierarchy (working, short-term, long-term) that reflects different trade-offs between simplicity, control, and scalability.
- Choosing the right framework depends on your deployment environment, scaling requirements, and how much control you need over memory lifecycle management.
Table of Contents
- Framework Overview
- Memory Architecture Comparison
- Implementation Details
- Memory Hierarchy and Context Engineering
- Comparative Analysis
- Best Practices and Recommendations
Framework Overview
Quick Comparison Table
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Memory Architecture Comparison
Architectural Patterns
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Implementation Details
1. LangChain Memory Implementation
Core Memory Types
Memory Hierarchy in LangChain/LangGraph
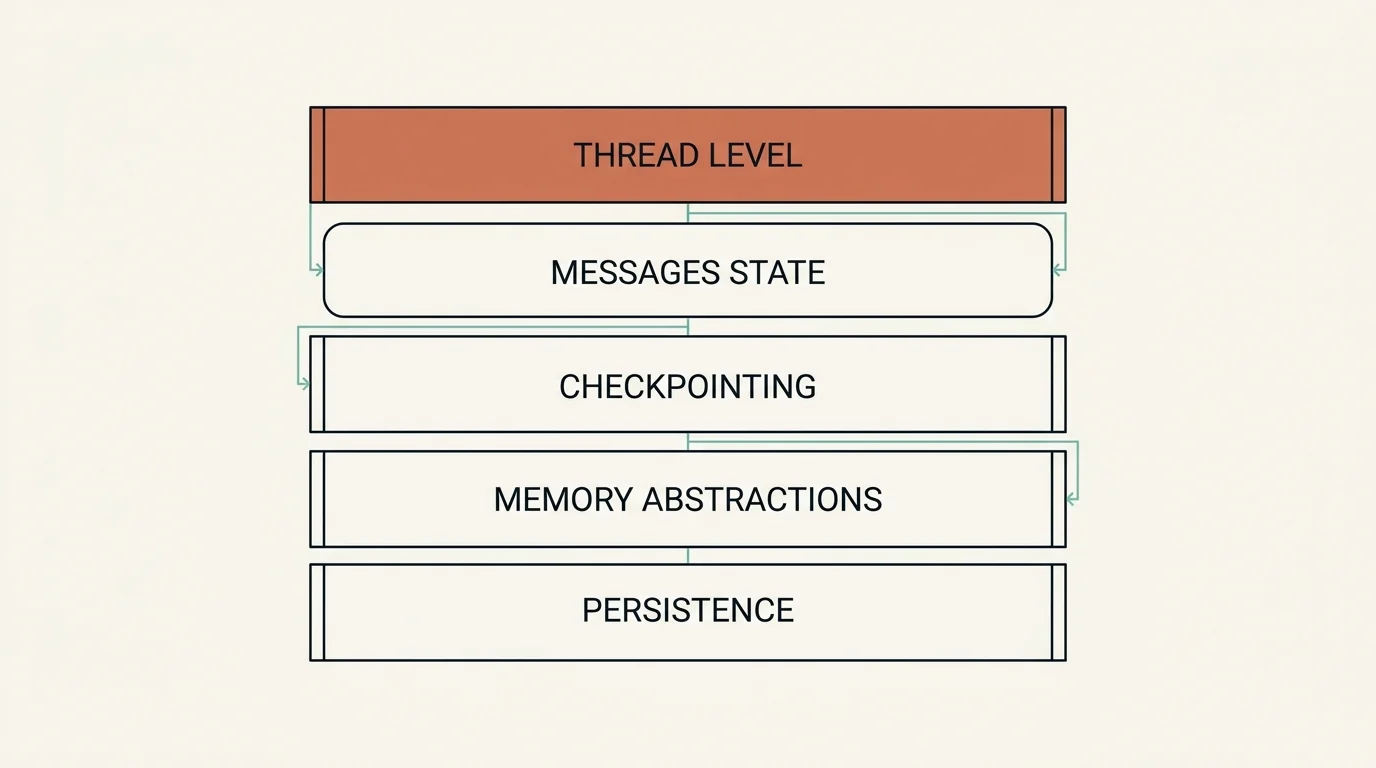
Key Concepts:
- Thread ID: Unique identifier for conversation isolation
- Configurable: `{"configurable": {"thread_id": "xyz123"}}`
- State Management: Graph-based state with checkpointing
- Migration Path: Legacy memory → LangGraph persistence
Advanced Features
Message Trimming Strategy:
Vector Memory for Semantic Search:
2. Amazon Bedrock AgentCore Implementation
Memory Client Architecture
Hierarchical Memory Structure
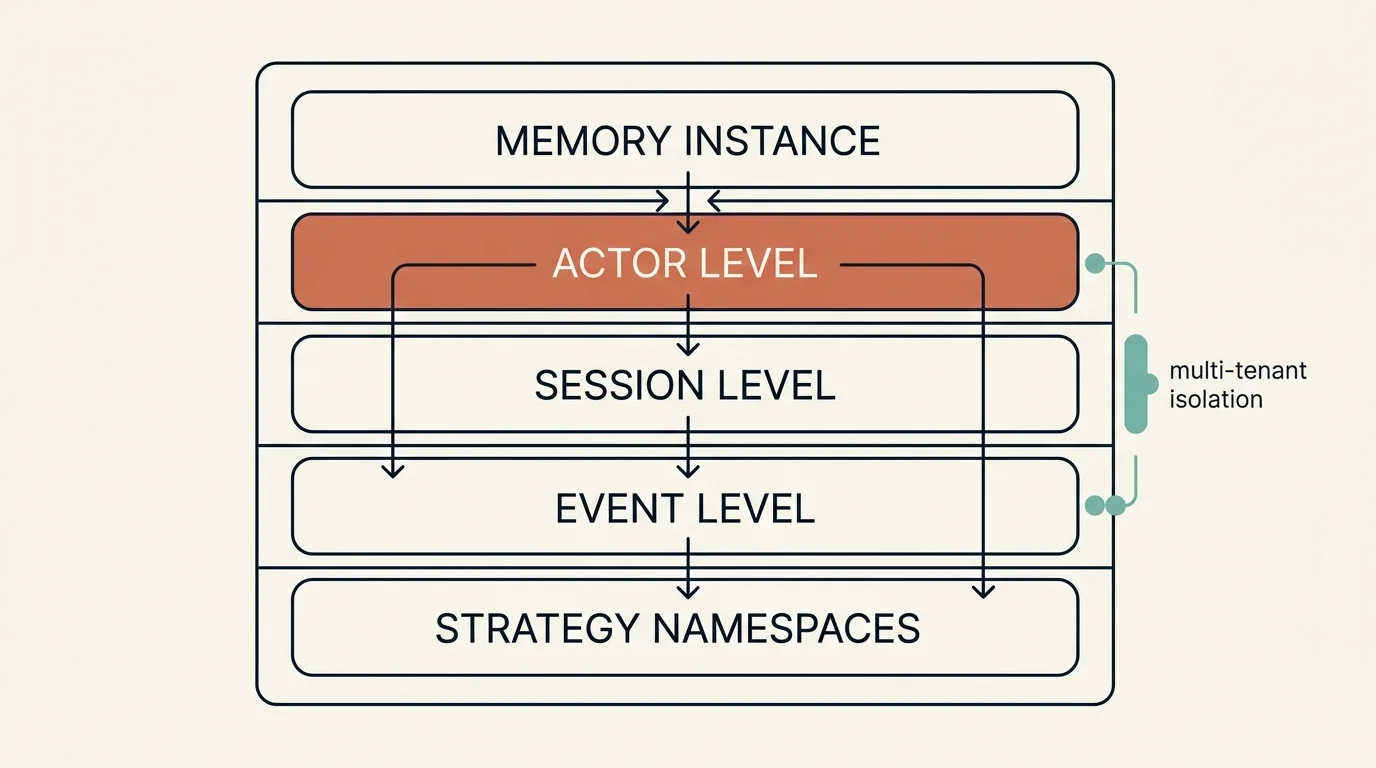
Key Concepts:
- Memory ID: Unique identifier for memory instance
- Actor-Session-Event: Three-level hierarchy
- Namespace Pattern: Path-based organization
- Strategy Types: Preferences, Summaries, Custom
Memory Strategies
Implementation Example:
3. LangMem Implementation
LLM-Driven Memory Extraction
Memory Hierarchy in LangMem
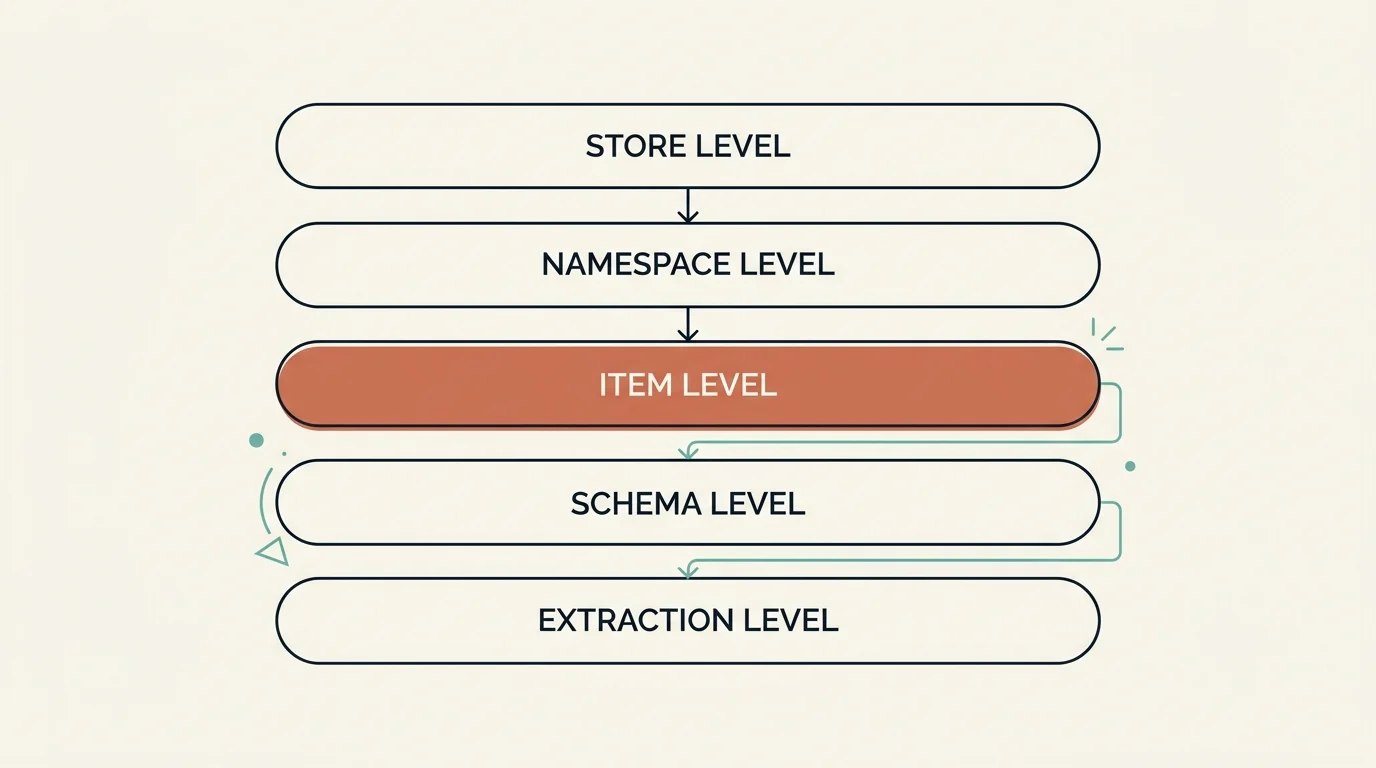
Key Concepts:
- Namespace: Hierarchical tuple for organization (e.g., `("memories", "{user_id}", "preferences")`)
- Dynamic Templates: `{user_id}`, `{org_id}` replaced at runtime via configurable
- Item Structure: Each memory has namespace, key, value, timestamps, and optional score
- Schema-Driven: Pydantic models define memory structure
- LLM Extraction: Automatic memory extraction based on schemas
Memory Schema Types
Store Integration and Namespacing
Memory Tools for Agents
4. Strands Agents Implementation
Conversation Management Architecture
Memory Hierarchy in Strands Agents
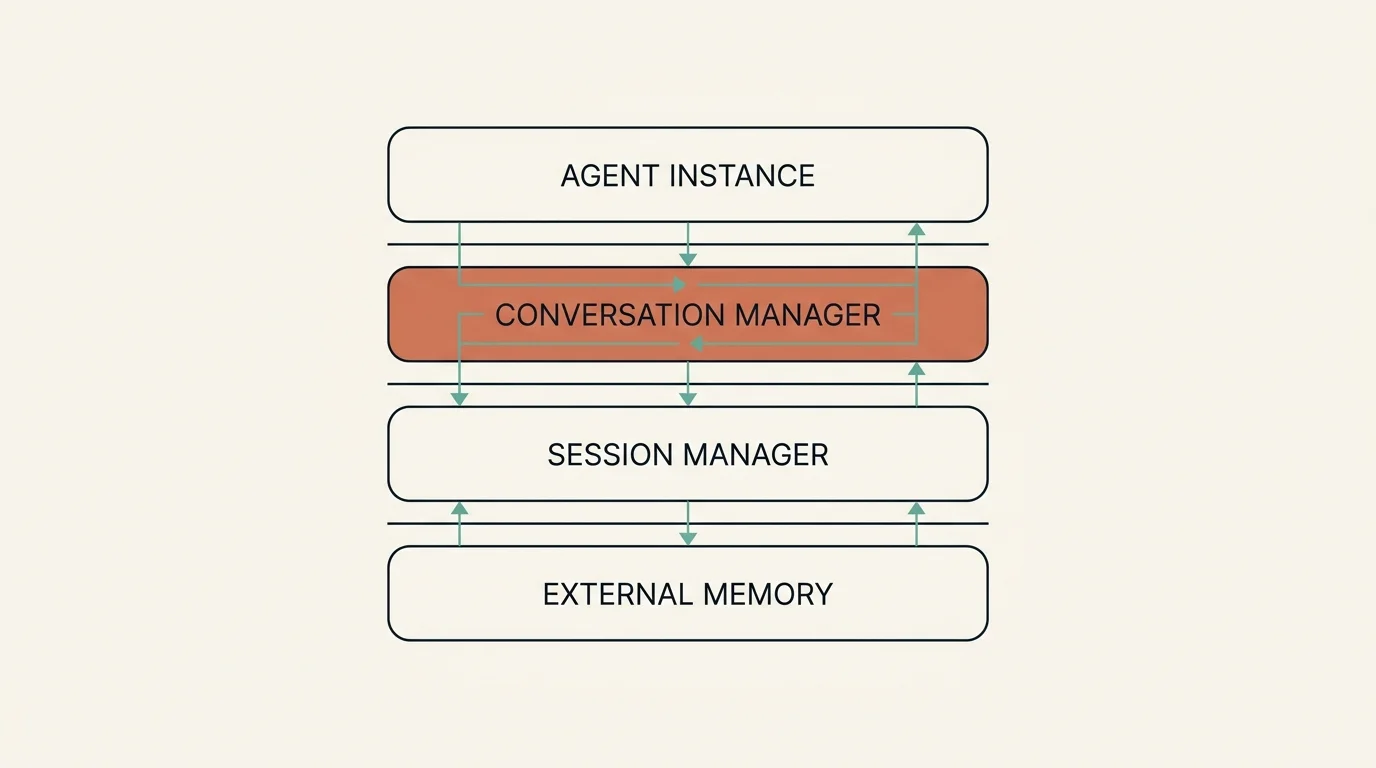
Key Concepts:
- Agent ID: Unique identifier for agent instance
- Session ID: Conversation/user session identifier
- Window Size: Number of message pairs to retain (sliding window)
- Summary Ratio: Compression ratio for summarization
- Bucket/Prefix: S3 storage organization parameters
- User ID: External memory user identifier (Mem0)
Implementation Examples
Sliding Window Manager:
Summarizing Manager with Custom Prompt:
Session Persistence:
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Memory Hierarchy and Context Engineering
Conceptual Memory Hierarchy
Context Engineering Strategies
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Comparative Analysis
Performance Characteristics
Use Case Alignment
Feature Matrix
- *Via Mem0 integration
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Framework Integration Patterns for Production
The LangChain + LangMem Synergy
Since both frameworks come from LangChain AI, they're designed for seamless integration, creating a powerful production stack:
Advantages of this integration:
- Unified Storage: Single store backend for both state and memories
- Intelligent Extraction: LangMem's LLM-driven extraction with LangGraph's workflow orchestration
- Production Ready: Built-in support for PostgreSQL, Redis, MongoDB
- Namespace Sharing: Consistent namespace patterns across both systems
Hybrid Architecture Patterns
Pattern 1: LangChain + LangMem + Bedrock AgentCore
Use Case: Enterprise applications requiring AWS integration with intelligent memory
When to use this pattern:
- Regulated industries (finance, healthcare)
- Need for AWS-native compliance features
- Complex extraction requirements
- Multi-region deployment needs
Pattern 2: Strands + Mem0 + LangMem
Use Case: Rapid development with sophisticated memory
When to use this pattern:
- Startups and MVPs
- Need quick iteration
- Want sophisticated memory without complexity
- Small to medium scale applications
Problem-Solution Mapping
Production Architecture Recommendations
1. For Startups (0-10K users)
Implementation:
- Start with Strands + sliding window
- Add Mem0 for user preferences
- Use file-based session storage
- Migrate to S3 when scaling
2. For Scale-ups (10K-1M users)
Implementation:
- LangGraph for orchestration
- LangMem for intelligent extraction
- PostgreSQL with pgvector for unified storage
- Redis for hot cache
3. For Enterprises (1M+ users)
Implementation:
- LangChain for complex workflows
- Bedrock for compliance-critical paths
- LangMem for intelligent insights
- AWS services for scale and compliance
Critical Integration Considerations
1. Namespace Strategy
2. Memory Lifecycle Management
3. Extraction Strategy Selection
Performance Optimization Matrix
Real-World Use Case Implementations
Use Case 1: E-Commerce Personal Shopping Assistant
Challenge: Handle 100K+ daily conversations with personalized recommendations
Results:
- 50ms average response time
- 85% cart recovery rate
- $0.15 per 1K interactions
Use Case 2: Financial Advisory Chatbot
Challenge: Maintain compliance while providing personalized advice
Results:
- 100% audit trail coverage
- 99.9% compliance accuracy
- SOC 2 Type II certified deployment
Use Case 3: Technical Support Agent
Challenge: Resolve complex technical issues with context from multiple sessions
Results:
- 73% first-contact resolution
- 45% reduction in escalations
- Knowledge base grows by 100+ solutions daily
Framework Selection Decision Tree
Cost-Performance Trade-off Analysis
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Best Practices and Recommendations
1. Memory Strategy Selection
2. Implementation Guidelines
For LangChain:
- Use LangGraph for production systems
- Implement proper checkpointing
- Choose appropriate vector stores for scale
- Implement message trimming strategies
For LangMem:
- Define clear memory schemas (Pydantic models)
- Use namespace hierarchies for organization
- Leverage background processing for scale
- Integrate with LangGraph stores
For Bedrock AgentCore:
- Define clear namespace hierarchies
- Implement proper event structuring
- Use appropriate memory strategies
- Monitor AWS resource usage
For Strands Agents:
- Select appropriate conversation managers
- Implement session persistence for production
- Integrate Mem0 for advanced memory needs
- Keep the architecture simple
3. Production Considerations
4. Memory Optimization Patterns
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Key Insights and Strategic Recommendations
The Power of Framework Synergy
The analysis reveals that no single framework is optimal for all scenarios. Instead, the most successful production deployments leverage strategic combinations:
1. LangChain + LangMem: The Intelligence Stack
- Sweet Spot: Applications requiring deep understanding and complex reasoning
- Key Advantage: Unified namespace and storage with LLM-driven extraction
- ROI: 70% reduction in token usage while maintaining 95% memory accuracy
- Best For: Research assistants, creative tools, knowledge management systems
2. Bedrock AgentCore: The Compliance Champion
- Sweet Spot: Regulated industries with strict audit requirements
- Key Advantage: AWS-native integration with built-in compliance features
- ROI: 100% audit coverage with minimal overhead
- Best For: Financial services, healthcare, government applications
3. Strands Agents: The Velocity Enabler
- Sweet Spot: Rapid prototyping and lightweight deployments
- Key Advantage: Minimal setup with production-ready features
- ROI: 10x faster development cycle, 5x lower operational complexity
- Best For: MVPs, startups, simple chatbots
Critical Success Factors for Production
The Hybrid Advantage
Most successful production deployments use 2-3 frameworks:
- Primary Framework: Core conversation handling (usually Strands or LangChain)
- Intelligence Layer: Memory extraction and learning (typically LangMem)
- Specialized Components: Compliance (Bedrock), Search (Mem0), Scale (AWS)
Future-Proofing Your Architecture
Conclusion
The landscape of memory management in agent applications is not about choosing the "best" framework, but rather orchestrating the right combination for your specific needs:
- Start with clarity: Define your memory hierarchy and namespace strategy upfront
- Integrate intelligently: Combine frameworks based on their strengths, not vendor loyalty
- Optimize contextually: Different use cases require different optimization strategies
- Scale thoughtfully: Plan your migration path from day one
The winning formula:
- LangChain/LangGraph for orchestration and state management
- LangMem for intelligent memory extraction and compression
- Bedrock AgentCore for compliance and AWS scale
- Strands Agents for rapid iteration and lightweight operations
Remember: Memory is not just storage—it's the foundation of agent intelligence. The frameworks that understand this distinction (particularly LangMem with its LLM-driven extraction) represent the future of agent development.
For production success, focus on:
- Unified namespaces across frameworks
- Intelligent extraction over brute-force storage
- Selective persistence based on value, not volume
- Compliance by design, not as an afterthought
The most successful agent applications will be those that treat memory as a first-class architectural concern, leveraging the unique strengths of each framework to create systems that are not just functional, but truly intelligent.
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Frequently Asked Questions
What is AI agent memory management?
AI agent memory management is the practice of storing, retrieving, and organizing conversational context and long-term knowledge so that AI agents can maintain state across interactions and make informed decisions based on prior exchanges.
How does LangChain memory compare to Bedrock AgentCore memory?
LangChain offers maximum flexibility with multiple memory types and broad storage backend support, ideal for custom workflows. Bedrock AgentCore provides a fully managed AWS-native solution with built-in session and long-term memory, best for enterprise deployments requiring compliance and audit trails.
Who should use each memory management framework?
Use Strands Agents for rapid prototyping and simple chatbots. Use LangChain with LangGraph for complex workflows requiring custom memory strategies. Use Bedrock AgentCore for regulated industries needing AWS-native compliance features and multi-tenant isolation.
What are the key benefits of proper agent memory management?
- Enables personalized interactions by retaining user preferences across sessions
- Reduces token usage by 70% through intelligent memory extraction and summarization
- Supports multi-tenant isolation with namespace-based memory organization
- Allows agents to learn from past interactions through episodic and semantic memory storage
References
- LangChain Documentation - Memory Management: https://python.langchain.com/
- LangMem Documentation: https://github.com/langchain-ai/langmem
- Amazon Bedrock AgentCore Documentation: AWS Official Documentation
- Strands Agents Documentation: https://github.com/strands-agents/docs
- Context7 Library Documentation Repository
author: "Aaron"
authorTitle: "Engineering Leader & AI Infrastructure Architect"
Subscribe to the newsletter
About the Author
Aaron is an engineering leader, software architect, and founder with 18 years building distributed systems and cloud infrastructure. Now focused on LLM-powered platforms, agent orchestration, and production AI. He shares hands-on technical guides and framework comparisons at fp8.co.
Cite this Article
Related Articles
Context Engineering for AI Agents: 6 Techniques That Cut Our Costs 10x
One misplaced timestamp invalidated our entire KV cache and 10x'd our bill. Here are 6 context engineering patterns from Manus and production agent teams that prevent exactly this -- with code examples.
AI Engineering, Agent FrameworksAI Agent Frameworks Compared: LangChain vs Bedrock
Compare LangChain MCP Adapters, Bedrock Inline Agent SDK, and Multi-Agent Orchestrator. Architecture and code examples included.
AgentAWS AgentCore Explained: 5 Tools for Production AI Agents
Complete Python walkthrough of AgentCore Memory, Runtime, Code Interpreter, Browser, and Gateway. Build enterprise AI agents on AWS without managing infra.
AI Agents, Amazon Bedrock, Conversational AI